I have created a pandas dataframe using this code:
import numpy as np
import pandas as pd
ds = {'col1': [1,2,3,3,3,6,7,8,9,10]}
df = pd.DataFrame(data=ds)
The dataframe looks like this:
print(df)
col1
0 1
1 2
2 3
3 3
4 3
5 6
6 7
7 8
8 9
9 10
I need to create a field called col2 that contains in a list (for each record) the last 3 elements of col1 while iterating through each record. So, the resulting dataframe would look like this:
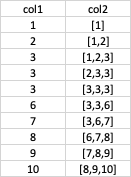
Does anyone know how to do it by any chance?
CodePudding user response:
Here is a solution using rolling and list comprehension
df['col2'] = [x.tolist() for x in df['col1'].rolling(3)]
col1 col2
0 1 [1]
1 2 [1, 2]
2 3 [1, 2, 3]
3 3 [2, 3, 3]
4 3 [3, 3, 3]
5 6 [3, 3, 6]
6 7 [3, 6, 7]
7 8 [6, 7, 8]
8 9 [7, 8, 9]
9 10 [8, 9, 10]
CodePudding user response:
Use a list comprehension:
N = 3
l = df['col1'].tolist()
df['col2'] = [l[max(0,i-N 1):i 1] for i in range(df.shape[0])]
Output:
col1 col2
0 1 [1]
1 2 [1, 2]
2 3 [1, 2, 3]
3 3 [2, 3, 3]
4 3 [3, 3, 3]
5 6 [3, 3, 6]
6 7 [3, 6, 7]
7 8 [6, 7, 8]
8 9 [7, 8, 9]
9 10 [8, 9, 10]
CodePudding user response:
lastThree = []
for x in range(len(df)):
lastThree.append([df.iloc[x - 2]['col1'], df.iloc[x - 1]['col1'], df.iloc[x]['col1']])
df['col2'] = lastThree
CodePudding user response:
Upon seeing the other answers, I'm affirmed my answer is pretty stupid. Anyways, here it is.
import pandas as pd
ds = {'col1': [1,2,3,3,3,6,7,8,9,10]}
df = pd.DataFrame(data=ds)
df['col2'] = df['col1'].shift(1)
df['col3'] = df['col2'].shift(1)
df['col4'] = (df[['col3','col2','col1']]
.apply(lambda x:','.join(x.dropna().astype(str)),axis=1)
)
The last column contains the resulting list.
col1 col4
0 1 1.0
1 2 1.0,2.0
2 3 1.0,2.0,3.0
3 3 2.0,3.0,3.0
4 3 3.0,3.0,3.0
5 6 3.0,3.0,6.0
6 7 3.0,6.0,7.0
7 8 6.0,7.0,8.0
8 9 7.0,8.0,9.0
9 10 8.0,9.0,10.0