create two tables for comparation:
create table t1(id integer primary key);
create table t2(id integer primary key, num integer);
insert into t1 values (0),(3),(6),(9);
insert into t2 values (0, 0), (3, 3), (6, 6), (9, 9);
start transaction tx1 and do a locking read for table t1:
start transaction;
select * from t1 where id >=3 and id < 8 for update;
The locks that tx1 holds look like this:
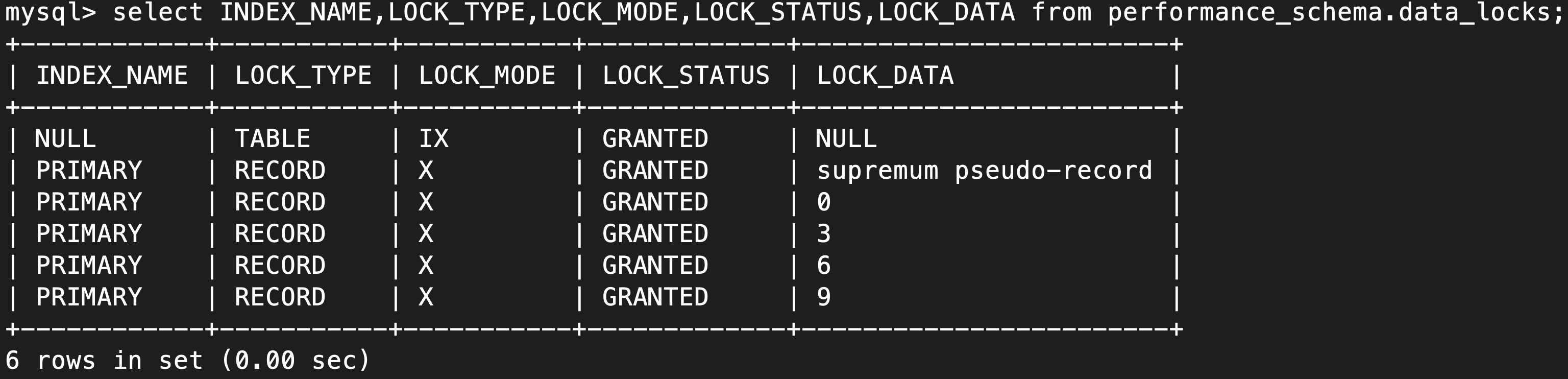
Now rollback tx1, start transaction tx2 and do a locking read for table t2:
start transaction;
select * from t2 where id >=3 and id < 8 for update;
The locks that tx2 holds look like this:
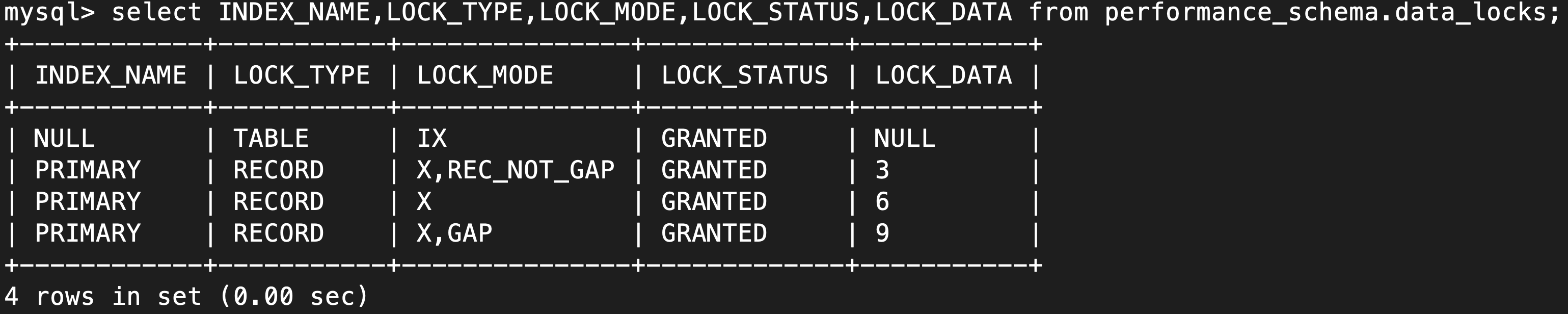
The behavior of tx2 conforms to my understanding of the mysql locking model. Why does tx1 lock every index record in table t1?
================ UPDATE ==================
Now using explain I saw some differences:
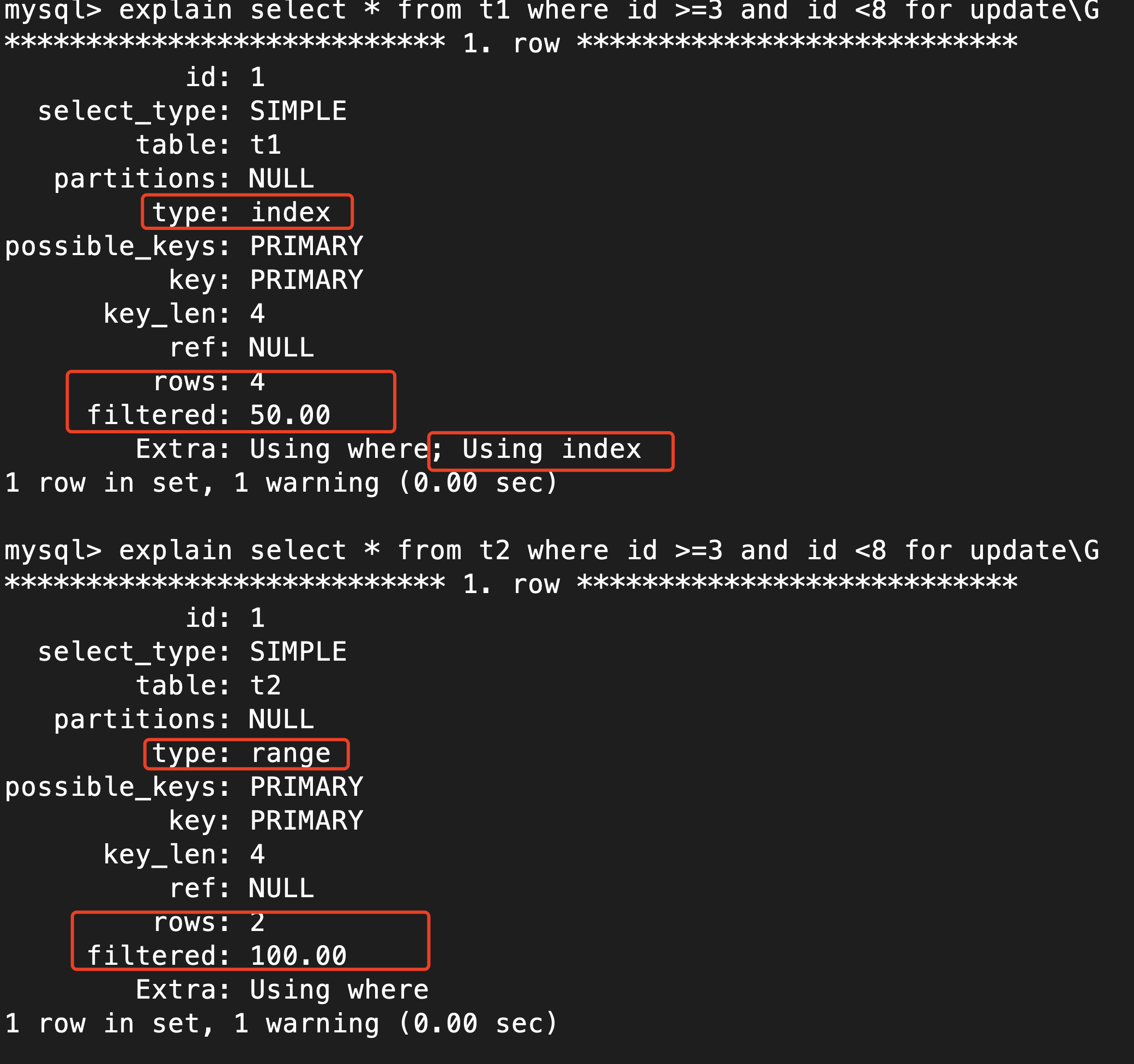
CodePudding user response:
All rows that are examined are locked.
The answer is in the EXPLAIN report. The query that does type: index is doing an index-scan, which examines every member of the index. In the case of the PRIMARY index, this effectively examines the whole table.
The query that does type: range is examining a subset of the rows.
The optimizer chose to do an index-scan for some reason. I'm not sure exactly why. It could depend on the version of MySQL you are using. You can check with this query: SELECT VERSION();
I believe this query is treated as an index-scan when it's a covering index. That is the EXPLAIN note that says "Using index." If the columns fetched by the query are the same columns in the index, then it's a covering index.
You get the same optimization strategy (index scan) if you test this query:
select id from t2 where id >=3 and id < 8 for update;
Because id is the column of the primary key index, and it's the only column returned by the query.