I have table in Python Pandas like below:
Input:
df = pd.DataFrame()
df["ID"] = [111,222,333]
df["TYPE"] = ["A", "A", "C"]
df["VAL_1"] = [1,3,0]
df["VAL_2"] = [0,0,1]
df:
ID | TYPE | VAL_1 | VAL_2
-----|-------|-------|-------
111 | A | 1 | 0
222 | A | 3 | 0
333 | C | 0 | 1
And I need to create pivot_table using code like below:
df_pivot = pd.pivot_table(df,
values=['VAL_1', 'VAL_2'],
index=['ID'],
columns='TYPE',
fill_value=0)
df_pivot.columns = df_pivot.columns.get_level_values(1) '_' df_pivot.columns.get_level_values(0)
df_pivot = df_pivot.reset_index()
df_pivot (result of above code):
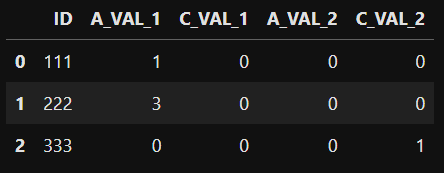
Requirements:
- Input df should have the following values in column "TYPE": A, B, C.
- However, input df is a result of some query in SQL, so sometimes there could be lack of some values (A, B, C) in column "TYPE"
- I need to check whether input df has all categories (A, B, C) in column "TYPE" if not in df_pivot create this category and fill by 0
Output: And I need something like below:
| ID | A_VAL_1 | C_VAL_1 | A_VAL_2 | C_VAL_2 | B_VAL_1 | B_VAL_2 |
|---|---|---|---|---|---|---|
| 111 | 1 | 0 | 0 | 0 | 0 | 0 |
| 222 | 3 | 0 | 0 | 0 | 0 | 0 |
| 333 | 0 | 0 | 0 | 0 | 0 | 0 |
As you can see value "B" was not in input df in column "TYPE", so in df_pivot was created columns with "B" (B_VAL_1, B_VAL_2) filling by 0.
How can I do that in Python Pandas ?
CodePudding user response:
You can get the "value" columns' names as well as the missing types in the "TYPE" column, take a cartesian product of them (e.g., (B, VAL_1)) and introduce those columns with 0 initialized and underscore-joined (e.g., B_VAL_1):
from itertools import product
val_cols = df.columns.difference(["ID", "TYPE"])
missings = pd.Index(["A", "B", "C"]).difference(df["TYPE"])
df_pivot[[*map("_".join, product(missings, val_cols))]] = 0
to get
>>> df_pivot
ID A_VAL_1 C_VAL_1 A_VAL_2 C_VAL_2 B_VAL_1 B_VAL_2
0 111 1 0 0 0 0 0
1 222 3 0 0 0 0 0
2 333 0 0 0 1 0 0
CodePudding user response:
Use a Categorical and the observed=False, dropna=False parameters in pivot_table:
df['TYPE'] = pd.Categorical(df['TYPE'], categories=['A', 'B', 'C'])
df_pivot = pd.pivot_table(df,
values=['VAL_1', 'VAL_2'],
index=['ID'],
columns='TYPE',
observed=False, dropna=False,
fill_value=0)
df_pivot.columns = df_pivot.columns.get_level_values(1).astype(str) '_' df_pivot.columns.get_level_values(0)
df_pivot = df_pivot.reset_index()
Output:
ID A_VAL_1 B_VAL_1 C_VAL_1 A_VAL_2 B_VAL_2 C_VAL_2
0 111 1 0 0 0 0 0
1 222 3 0 0 0 0 0
2 333 0 0 0 0 0 1