I have a dataframe with group, value and columns based in rollaply mean of the last n values, just like that:
library(dplyr); library(zoo)
df = data.frame( group = c(rep(1,5), rep(2,5)),
value = c(23,14,53,12,56,32,65,76,36,74)) %>%
group_by(group) %>%
mutate(
roll1 = rollapplyr(value, 1, mean, fill = NA, na.rm = T, partial = F),
roll2 = rollapplyr(value, 2, mean, fill = NA, na.rm = T, partial = F),
roll3 = rollapplyr(value, 3, mean, fill = NA, na.rm = T, partial = F)
)
df
group value roll1 roll2 roll3
1 1 23 23 NA NA
2 1 14 14 18.5 NA
3 1 53 53 33.5 30
4 1 12 12 32.5 26.3
5 1 56 56 34 40.3
6 2 32 32 NA NA
7 2 65 65 48.5 NA
8 2 76 76 70.5 57.7
9 2 36 36 56 59
10 2 74 74 55 62
The 'rolln' column represents the average of the last n values.
Then I would like to summarize in a new dataframe which group of values provided the highest average. Remembering that the roll3 column, for example, has a set of 3 values.
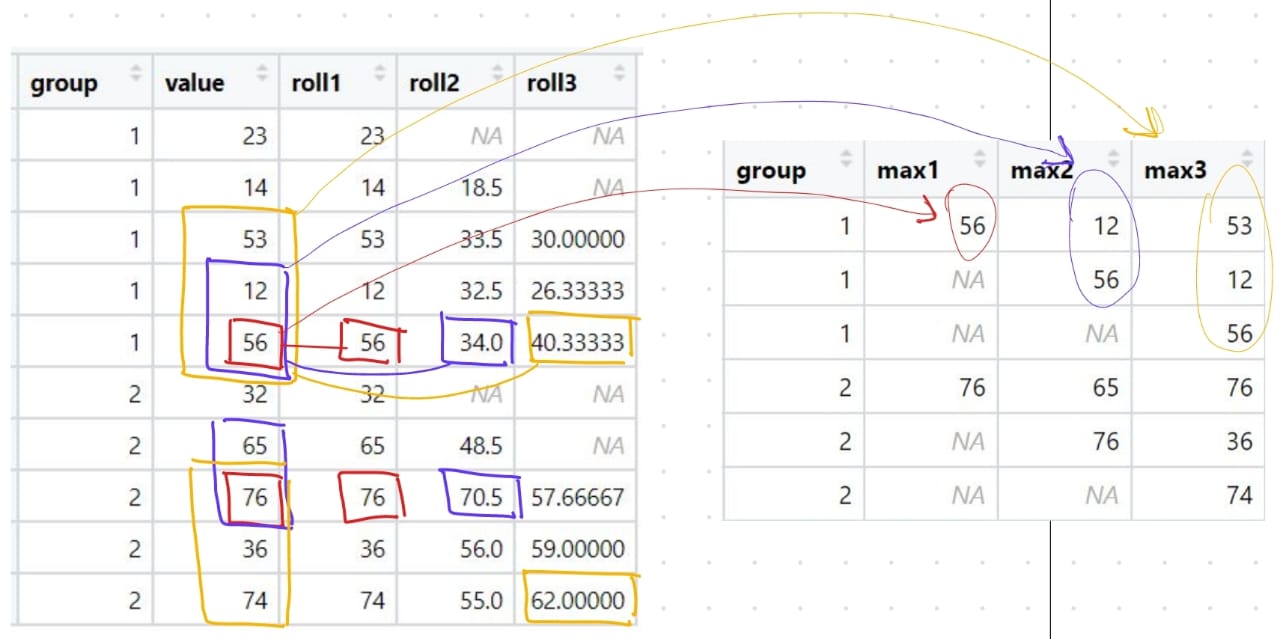
I tried to use which.max function, but without success. The position of NA's in the final data.frame isn't important
Thanks in advance
CodePudding user response:
I'd love to see a more concise solution, but this seems to work:
library(tidyverse)
df %>%
pivot_longer(starts_with("roll"), values_to = "avg") %>%
filter(!is.na(avg)) %>%
group_by(group, name) %>%
filter(slider::slide_dbl(avg, max, .after = 2) == max(avg)) %>% # EDIT #2
#filter(avg == max(avg) |
# lead(avg, default = 0) == max(avg) |
# lead(avg, 2, default = 0) == max(avg)) %>%
mutate(items = n() 1 - parse_number(name)) %>% # EDIT
slice(items:n()) %>%
mutate(row = row_number()) %>%
select(-avg, -items) %>%
pivot_wider(names_from = name, values_from = value)
Result
group row roll1 roll2 roll3
<dbl> <int> <dbl> <dbl> <dbl>
1 1 1 56 12 53
2 1 2 NA 56 12
3 1 3 NA NA 56
4 2 1 76 65 76
5 2 2 NA 76 36
6 2 3 NA NA 74