I am new to using XPath and was confused about how to retrieve text that is wrapped in href (where I do not need href info.).
URL I am using:

Where I want to extract text "Gonzalo Pineda" and the code I have written is this
import requests
from lxml import HTML
t = requests.get("https://en.wikipedia.org/wiki/2022_Major_League_Soccer_season")
dom_tree = html.fromstring(t.content)
coach = updated_dom_tree.xpath('//table[contains(@class, "wikitable")][2]//tbody/tr/td[2]/text()')
Where this is second table from a Wikipedia page so that's why I wrote //table[contains(@class, "wikitable")][2].
Then I wrote //tbody/tr/td[2]/text() just following the HTML structure. However, the outcome of the code returns " " (empty string with \n") without actual text info.
I tried to change the code to a[contains(@href, "wiki")] after searching through the stack overflow but I was getting an output of an empty list ([]).
I would really appreciate it if you could help me with this!
Edit: I can't copy-paste HTML because I just got that from inspect tool (F12).
The HTML line can be found in "Personnel and sponsorships" table second column. Thank you!
CodePudding user response:
this is the approach you can take the extract the table. extra import pandas just to see how the table data is coming along.
import requests
from lxml import html
import pandas as pd # to data storage, using pandas
t = requests.get("https://en.wikipedia.org/wiki/2022_Major_League_Soccer_season")
dom_tree = html.fromstring(t.content)
#coach = updated_dom_tree.xpath('//table[contains(@class, "wikitable")][2]//tbody/tr/td[2]/text()')
table_data=[]
table_header=[]
table=dom_tree.xpath("//table")[2]
for e_h in table.findall(".//tr")[0]:
table_header.append(e_h.text_content().strip())
table_data={0:[],1:[],2:[],3:[],4:[]}
for e_tr in table.findall(".//tr")[1:]:
col_no=0
for e_td in e_tr.findall(".//td"):
if e_td.text_content().strip():
table_data[col_no].append(e_td.text_content().strip())
else:
table_data[col_no].append('N/A') # handle spaces,
if e_td.get('colspan') == '2': ## handle example team Colorado Rapids, where same td spans
col_no =1
table_data[col_no].append('N/A')
else:
col_no =1
for i in range(0,5):
table_data[table_header[i]] = table_data.pop(i)
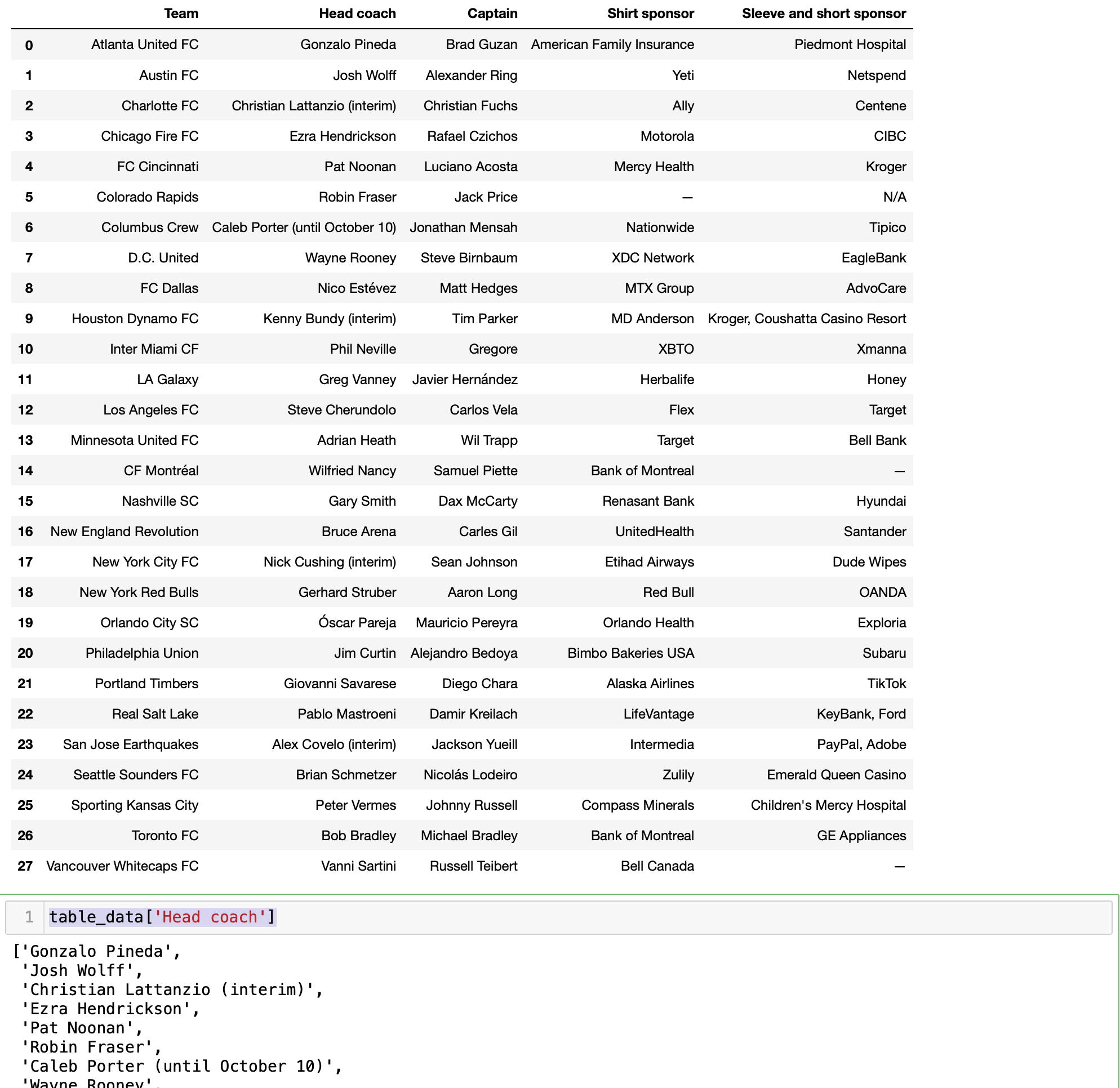
df=pd.DataFrame(table_data)
if just want Head Coach column, then table_data['Head coach'] will give those.
output:
CodePudding user response:
If I understand you correctly, what you are looking for is
dom_tree.xpath('(//table[contains(@class, "wikitable")]//span[@])[1]//following-sibling::span//a/text()')[0]
Output should be
'Gonzalo Pineda'
EDIT:
To get the name of all head coaches, try:
for coach in dom_tree.xpath('(//table[contains(@class, "wikitable")])[2]//tbody//td[2]'):
print(coach.xpath('.//a/text()')[0])
Another way to do it - using pandas
import pandas as pd
tab = dom_tree.xpath('(//table[contains(@class, "wikitable")])[2]')[0]
pd.read_html(HTML.tostring(tab))[0].loc[:, 'Head coach']