Re-purposing a previous question but hopefully with more clarity dput().
I'm working with the data below that almost similar to a key:value pairing such that every "type" variable has a corresponding variable that contains a "total" value across each row.
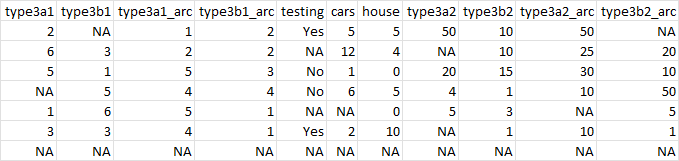
structure(list(type3a1 = c(2L, 6L, 5L, NA, 1L, 3L, NA), type3b1 = c(NA,
3L, 1L, 5L, 6L, 3L, NA), type3a1_arc = c(1L, 2L, 5L, 4L, 5L,
4L, NA), type3b1_arc = c(2L, 2L, 3L, 4L, 1L, 1L, NA), testing = c("Yes",
NA, "No", "No", NA, "Yes", NA), cars = c(5L, 12L, 1L, 6L, NA,
2L, NA), house = c(5L, 4L, 0L, 5L, 0L, 10L, NA), type3a2 = c(50L,
NA, 20L, 4L, 5L, NA, NA), type3b2 = c(10L, 10L, 15L, 1L, 3L,
1L, NA), type3a2_arc = c(50L, 25L, 30L, 10L, NA, 10L, NA), type3b2_arc = c(NA,
20L, 10L, 50L, 5L, 1L, NA), X = c(NA, NA, NA, NA, NA, NA, NA)), class = "data.frame", row.names = c(NA,
-7L))
I am trying to do a summation loop that goes through every row, and scans each "type" variable (i.e. type3a1, type3b1, type3c1, etc.). Each "type" has a matching variable that contains its "total" value (i.e. type3a2, type3b2, type3c2, etc.)
Process:
- Check if the "type" variable contains values in (1,2,3,4 or 5).
- If that type column's [row,col] value is in (1:5), then move 7 columns from its current [row,col] index to grab it's total value and ready for summation.
- After checking every "type" variable, sum all the gathered "total" values and plop into a new overall totals column.
Essentially, I want to end up with a total value like the one below:
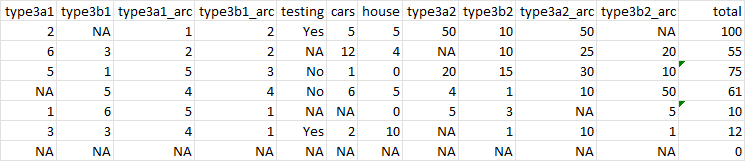
The first row shows a total of 100 since type3b1 has a value of "NA" which is not in (1:5). Hence, its total pairing (i.e. 7 columns away = cell value of "10") is not accounted for in the row summation.
My approach this time compared to a previous attempt is using a for loop and relying on indexing based on how far a column was away from another column. I was having a lot of trouble approaching this using dplyr / mutate methods and was having a lot of issues with the variability in the type:total name pairings (i.e. no pattern in the naming conventions, very messy data)...
# Matching pairing variables (i.e. type_vars:"type3a1" with total_vars:"type3a2")
type_vars <- c("type3a1", "type3b1", "type3a1_arc", "type3b1_arc")
total_vars <- c("type3a2", "type3b2", "type3a2_arc", "type3b2_arc")
valid_list <- c(1,2,3,4,5)
totals = list()
for(row in 1:nrow(df)) {
sum = 0
for(col in type_vars) {
if (df[row,col] %in% valid_list) {
sum <- sum (df[row,col 7])
}
}
totals <- sum
}
I'm hoping this is the right approach but in either case, the code gives me an error at the sum <- sum (df[row,col 7]) line where: Error in col 7 : non-numeric argument to binary operator.
It's weird since if I were to do this manually and just indicate df[1,1 2], it gives me a value of "1" which is the value of the intersect [row1, type3a1_arc] in the df above.
Any help or assistance would be appreciated.
CodePudding user response:
Here is one way with tidyverse - loop across the columns with names that matches the 'type' followed by one or more digits (\\d ), a letter ([a-z]) and the number 2, then get the corresponding column name by replacing the column name (cur_column()) substring digit 2 with 1, get the value using cur_data(), create a logical vector with %in%, negate (!) and replace those not in 1:5 to NA, then wrap with rowSums and na.rm = TRUE to get the total
library(dplyr)
library(stringr)
df1 %>%
mutate(total = rowSums(across(matches('^type\\d [a-z]2'), ~
replace(.x, !cur_data()[[str_replace(cur_column(),
"(\\d [a-z])\\d ", "\\11")]] %in% 1:5, NA)), na.rm = TRUE))
-output
type3a1 type3b1 type3a1_arc type3b1_arc testing cars house type3a2 type3b2 type3a2_arc type3b2_arc X total
1 2 NA 1 2 Yes 5 5 50 10 50 NA NA 100
2 6 3 2 2 <NA> 12 4 NA 10 25 20 NA 55
3 5 1 5 3 No 1 0 20 15 30 10 NA 75
4 NA 5 4 4 No 6 5 4 1 10 50 NA 61
5 1 6 5 1 <NA> NA 0 5 3 NA 5 NA 10
6 3 3 4 1 Yes 2 10 NA 1 10 1 NA 12
7 NA NA NA NA <NA> NA NA NA NA NA NA NA 0
Or may also use two across (assuming the columns are in order)
df1 %>%
mutate(total = rowSums(replace(across(8:11),
!across(1:4, ~ .x %in% 1:5), NA), na.rm = TRUE))
-output
type3a1 type3b1 type3a1_arc type3b1_arc testing cars house type3a2 type3b2 type3a2_arc type3b2_arc X total
1 2 NA 1 2 Yes 5 5 50 10 50 NA NA 100
2 6 3 2 2 <NA> 12 4 NA 10 25 20 NA 55
3 5 1 5 3 No 1 0 20 15 30 10 NA 75
4 NA 5 4 4 No 6 5 4 1 10 50 NA 61
5 1 6 5 1 <NA> NA 0 5 3 NA 5 NA 10
6 3 3 4 1 Yes 2 10 NA 1 10 1 NA 12
7 NA NA NA NA <NA> NA NA NA NA NA NA NA 0
Or using base R
df1$total <- rowSums(mapply(\(x, y) replace(y, !x %in% 1:5, NA),
df1[1:4], df1[8:11]), na.rm = TRUE)
df1$total
[1] 100 55 75 61 10 12 0
CodePudding user response:
Here’s a base R solution:
valid_vals <- sapply(type_vars, \(col) df[, col] %in% valid_list)
temp <- df[, total_vars]
temp[!valid_vals] <- NA
df$total <- rowSums(temp, na.rm = TRUE)
df$total
# [1] 100 55 75 61 10 12 0