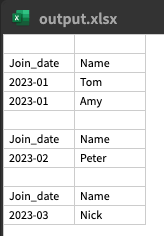
The dataframe is created with the Join_Date and Name
data = {'Join_Date': ['2023-01', '2023-01', '2023-02', '2023-03'],
'Name': ['Tom', 'Amy', 'Peter', 'Nick']}
df = pd.DataFrame(data)
I have split the df by Join_Date, can it be printed into excel date by date by using for loop?
df_split = [df[df['Join_Date'] == i] for i in df['Join_Date'].unique()]
Expected result:
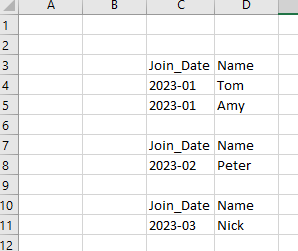
CodePudding user response:
You can use the ExcelWriter method in pandas:
import pandas as pd
import xlsxwriter
data = {'Join_Date': ['2023-01', '2023-01', '2023-02', '2023-03'],
'Name': ['Tom', 'Amy', 'Peter', 'Nick']}
df = pd.DataFrame(data)
df_split = [df[df['Join_Date'] == i] for i in df['Join_Date'].unique()]
writer = pd.ExcelWriter("example.xlsx", engine='xlsxwriter')
skip_rows = 0
for df in df_split:
df.to_excel(writer, sheet_name='Sheet1', startcol=2, startrow=2 skip_rows, index=False)
skip_rows = df.shape[0] 2
writer.close()
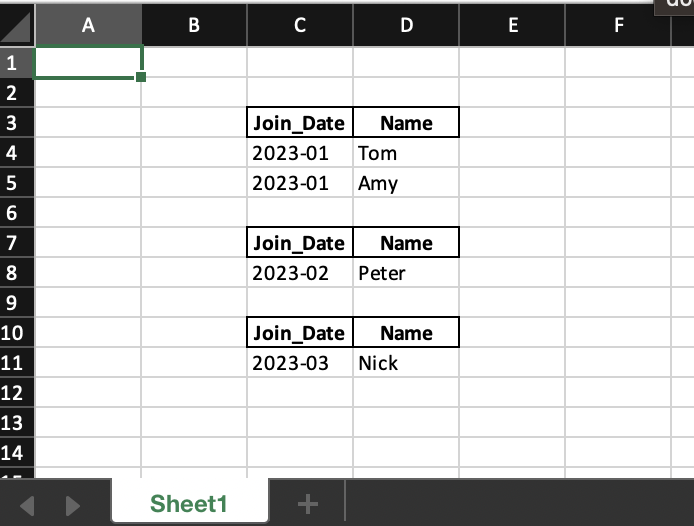
CodePudding user response:
You can use the pandas methods to do so, like this. (You can add a empty line if you really need it)
import pandas as pd
data = {'Join_Date': ['2023-01', '2023-01', '2023-02', '2023-03'],
'Name': ['Tom', 'Amy', 'Peter', 'Nick']}
df = pd.DataFrame(data)
def add_header(x):
x.loc[-1] = 'Join_date', 'Name'
return x.sort_index().reset_index(drop=True)
df_split = df.groupby(['Join_Date'], group_keys=False)
df_group = df_split.apply(add_header)
df_group.to_excel('output.xlsx', index=False, header=False)
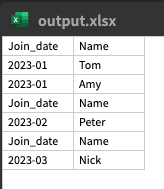
You can add the empty line editing the add_header func like:
def add_header(x):
x.loc[-1] = ' ', ' '
x = x.sort_index().reset_index(drop=True)
x.loc[0.5] = 'Join_date', 'Name'
x = x.sort_index().reset_index(drop=True)
return x