There is some legacy code that I am convinced could be replaced in a more elegant and robust solution.
A series of flags are used to identify the classification of a row. A simplified example:
case when flag1 is True
and flag2 is True
and flag3 is True then 'ABC',
case when flag1 is False
and flag2 is True
and flag3 is True then 'DEF',
the challenge arises as not all flags are used in the case statements. The code continues:
case when flag3 is True
and flag4 is False then 'CEA',
etc.
I had thought of having a reference table which would have all classification combinations and could then be joined to the flags to get the classifications.
| flag1 | flag2 | flag3 | flag4 | classification |
|---|---|---|---|---|
| True | True | True | ABC | |
| False | True | True | DEF | |
| ... | ... | ... | ... | ... |
| True | False | CEA |
Because of way I've had the joins working, all flags are required and I have not found a way to join just flag1, flag2, and flag3 for the first case and just flag3 and flag4 for the last case, etc. It is acceptable for flag4 to be any value for the first two cases ('ABC' and 'DEF'), and so on for other cases where the flags are not explicitly defined.
The code I'm looking as has nearly 10000 lines of these case statements. There are no rules found that simplify the classifications enough to generate them in some other way.
Is there an elegant way to replace repetitive case statements as seen in this example?
I believe a reference table or similar solution would be ideal, as it would avoid code changes if any cases are added or modified.
CodePudding user response:
I'm not proficient on Bigquery but in Oracle I would do something like this:
from
data d
join
classification c
on coalesce(c.flag1, d.flag1, False) = coalesce(d.flag1, False)
and coalesce(c.flag2, d.flag2, False) = coalesce(d.flag2, False)
...
The idea is if the classification reference table doesn't care about a flag, you just compare the base table's flag against itself. The False defaults are there to handle cases where the base table has a null flag.
The main thing to be careful of when joining like this is you lose the "first match" short circuit of a CASE statement and your base row could easily end up joining to multiple reference rows. You'll want a priority column on the reference table you can sort out the "first match" after joining.
CodePudding user response:
Consider below for BigQuery
with classifications as (
select True flag1, True flag2, True flag3, null flag4, 'ABC' classification union all
select False, True, True, null, 'DEF' union all
select null, null, True, False, 'CEA'
)
select *,
(
select classification
from classifications
where if(flag1 is null, true, flag1 = t.flag1)
and if(flag2 is null, true, flag2 = t.flag2)
and if(flag3 is null, true, flag3 = t.flag3)
and if(flag4 is null, true, flag4 = t.flag4)
limit 1
) as classification
from your_table t
you can test it using below dummy data for your_table
with your_table as (
select true flag1, true flag2, true flag3, true flag4 union all
select false, true, true, false union all
select false, false, true, false
), classifications as (
select True flag1, True flag2, True flag3, null flag4, 'ABC' classification union all
select False, True, True, null, 'DEF' union all
select null, null, True, False, 'CEA'
)
select *,
(
select classification
from classifications
where if(flag1 is null, true, flag1 = t.flag1)
and if(flag2 is null, true, flag2 = t.flag2)
and if(flag3 is null, true, flag3 = t.flag3)
and if(flag4 is null, true, flag4 = t.flag4)
limit 1
) as classification
from your_table t
with output
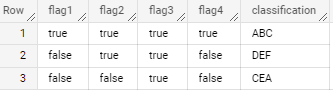
CodePudding user response:
You can use the below solution to get one row per classification of your choice. Only thing is: you have to keep the classification rules hardcoded inside the query (which may or may not be fine depending on your code):
-- this is your raw data
with data as (
select true as flag1, true as flag2, true as flag3, true as flag4
union all
select false as flag1, true as flag2, true as flag3, false as flag4
union all
select null as flag1, false as flag2, false as flag3, true as flag4
)
select distinct p.flag1, p.flag2, p.flag3, p.flag4, p.classification from data, unnest([
struct(
flag1 as flag1,
flag2 as flag2,
flag3 as flag3,
flag4 as flag4,
if(flag1 is true and flag2 is true and flag3 is true, 'ABC', null) as classification
), -- rule#1
struct(
flag1 as flag1,
flag2 as flag2,
flag3 as flag3,
flag4 as flag4,
if(flag1 is false and flag2 is true and flag3 is true, 'DEF', null) as classification
), -- rule#2
struct(
flag1 as flag1,
flag2 as flag2,
flag3 as flag3,
flag4 as flag4,
if(flag3 is true and flag4 is false, 'CEA', null) as classification
), -- rule#3
struct(
flag1 as flag1,
flag2 as flag2,
flag3 as flag3,
flag4 as flag4,
if(flag2 is true, 'XYZ', null) as classification
) -- rule#4
]) as p
where p.classification is not null