I am getting different results when I run the sum() function in pandas compared to the totals which show up in Excel. I am pivoting the dataframe in pandas to get different views of the data and check if theres a difference between the totals in pandas and excel.
The complete dataframe ('merged_data') is available as a .csv file here: [https://github.com/yyshastri/NZ-Police-Community-Dataset/blob/7562ae2d9b8c4337d9ad8bd436f5d355826820b0/Merged_Community_Police_Data_v2.xlsx][1]
The code is as below:
# select Auckland and the far North district
TA_data = merged_data[merged_data['TA2018_name'].isin(['Auckland','Far North District'])].copy()
dfp2 = TA_data.pivot_table(index='Year', columns='crime', values='Reported Incidents', aggfunc='sum')
dfp2.head()
This is the result of the above code:
| crime | Abduction | Assault | Blackmail | Illegal Use of Motor Vehicle | Illegal Use of Property | Robbery | Sexual Assault | Theft (Other) | Theft From Retail Premises | Theft From a Person | Theft from a Motor Vehicle | Theft of a Motor Vehicle | Unlawful Entry, B&E |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Year | |||||||||||||
| 2018 | 96 | 6095 | 56 | 10548 | 491 | 1202 | 541 | 12831 | 8670 | 573 | 10654 | 52 | 19873 |
| 2019 | 92 | 7042 | 85 | 11014 | 703 | 1213 | 596 | 15893 | 10012 | 670 | 12665 | 42 | 22910 |
| 2020 | 67 | 7135 | 90 | 9335 | 493 | 961 | 661 | 15182 | 11517 | 556 | 8883 | 30 | 18791 |
There is a variance of anywhere between 6 to 200 between the total from pandas vis-a-vis Excel. For example, the category of "Assault" for 2020 gives 7135 in the df but in Excel it shows 7723.
I might be missing the obvious but would appreciate any pointers.
[1]: 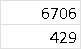 which equals to 7135.
which equals to 7135.
Here is also another way in python to find 7135 incidents without pivoting the table:
merged_data["Reported Incidents"][(merged_data["crime"]=="Assault")&(merged_data["Reported Incidents"]>=1)& (merged_data["Year"]==2020)&(merged_data["TA2018_name"].isin(["Auckland","Far North District"]))].sum()
#output
7135