I have a pandas dataframe with gaps in time series.
It looks like the following:
Example Input
--------------------------------------
Timestamp Close
2021-02-07 09:30:00 124.624
2021-02-07 09:31:00 124.617
2021-02-07 10:04:00 123.946
2021-02-07 16:00:00 123.300
2021-02-09 09:04:00 125.746
2021-02-09 09:05:00 125.646
2021-02-09 15:58:00 125.235
2021-02-09 15:59:00 126.987
2021-02-09 16:00:00 127.124
Desired Output
--------------------------------------------
Timestamp Close
2021-02-07 09:30:00 124.624
2021-02-07 09:31:00 124.617
2021-02-07 09:32:00 124.617
2021-02-07 09:33:00 124.617
'Insert a line for each minute up to the next available
timestamp with the Close value form the last available timestamp'
2021-02-07 10:03:00 124.617
2021-02-07 10:04:00 123.946
2021-02-07 16:00:00 123.300
'I dont want lines inserted here. As this date is not
present in the original dataset (could be a non trading
day so I dont want to fill this gap)'
2021-02-09 09:04:00 125.746
2021-02-09 09:05:00 125.646
2021-02-09 15:58:00 125.235
'Fill the gaps here again but only between 09:30 and 16:00 time'
2021-02-09 15:59:00 126.987
2021-02-09 16:00:00 127.124
What I have tried is:
'# set the index column'
df_process.set_index('Exchange DateTime', inplace=True)
'# resample and forward fill the gaps'
df_process_out = df_process.resample(rule='1T').ffill()
'# filter and return only timestamps between 09:30 and 16:00'
df_process_out = df_process_out.between_time(start_time='09:30:00', end_time='16:00:00')
However if I do it like this it also resamples and generates new timestamps on dates that are not existent in the original dataframe. In the example above it would also generate timestamps on a minute basis for 2021-02-08
How can I avoid this?
Furthermore is there a better way to avoid resampling over the whole time.
df_process_out = df_process.resample(rule='1T').ffill()
This generates timestamps from 00:00 to 24:00 and in the next line of code I have to filter most timestamps out again. Doesn't seem efficient.
Any help/guidance would be highly appreciated
Thanks
Edit:
As requested a small sample set
df_in: Input data
df_out_error: Wrong Output Data
df_out_OK: How the output data should look like
In the following ColabNotebook I prepeared a small sample.
Explanation
1. Resampling for limited time period only
"Furthermore is there a better way to avoid resampling over the whole time. This generates timestamps from 00:00 to 24:00 and in the next line of code I have to filter most timestamps out again. Doesn't seem efficient."
As in the above solution, you can resample and then ffill (or any other type of fill) using rule = 1Min. This ensures that you are not resampling from 00:00 to 24:00 but only from the start to end time stamps available in your data. To prove, I show this applied to a single date in the data -
#filtering for a single day
ddd = df[df['date']==df.date.unique()[0]]
#applying resampling on that given day
ddd.set_index('Timestamp').resample('1Min').ffill()
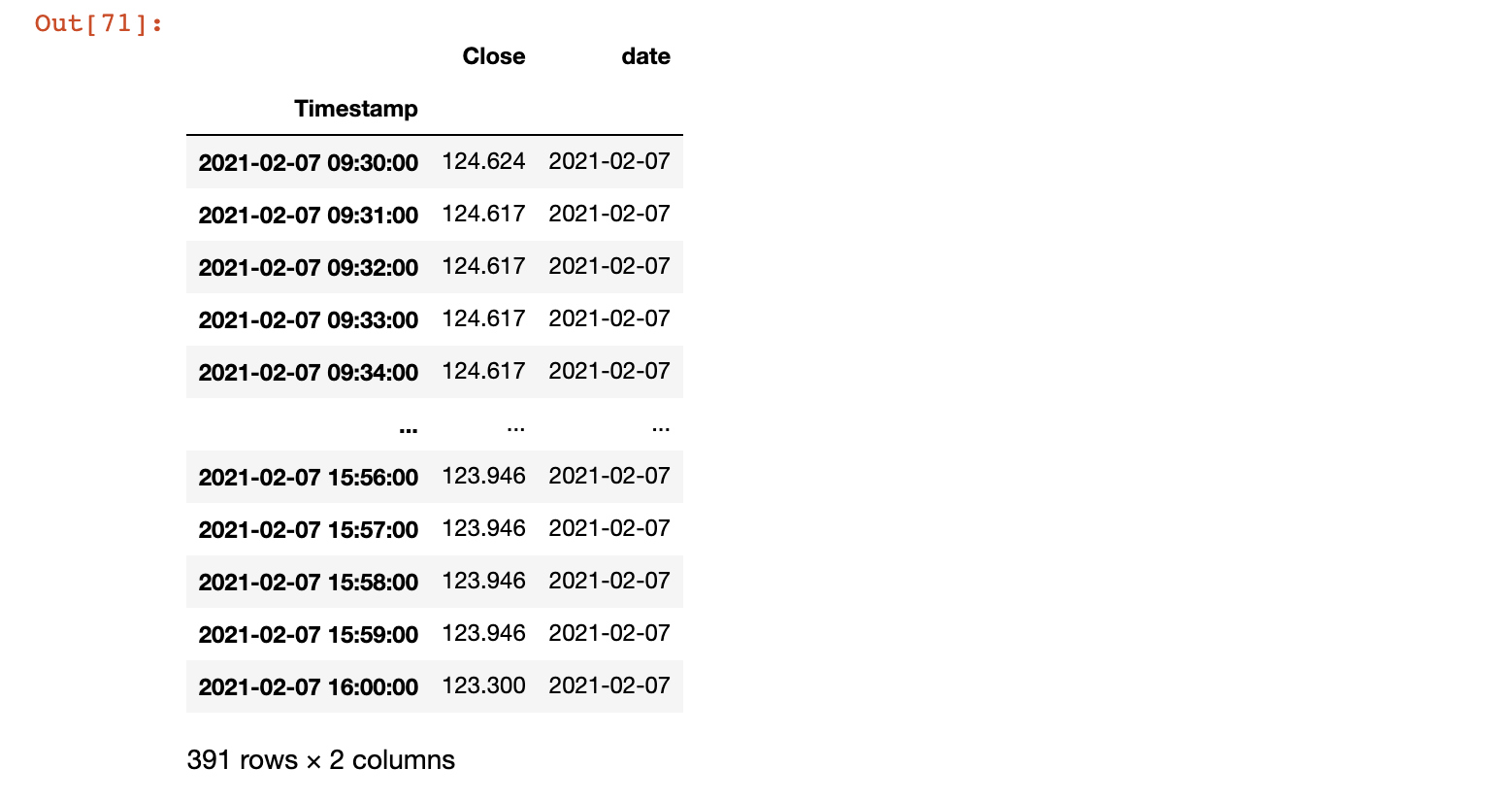
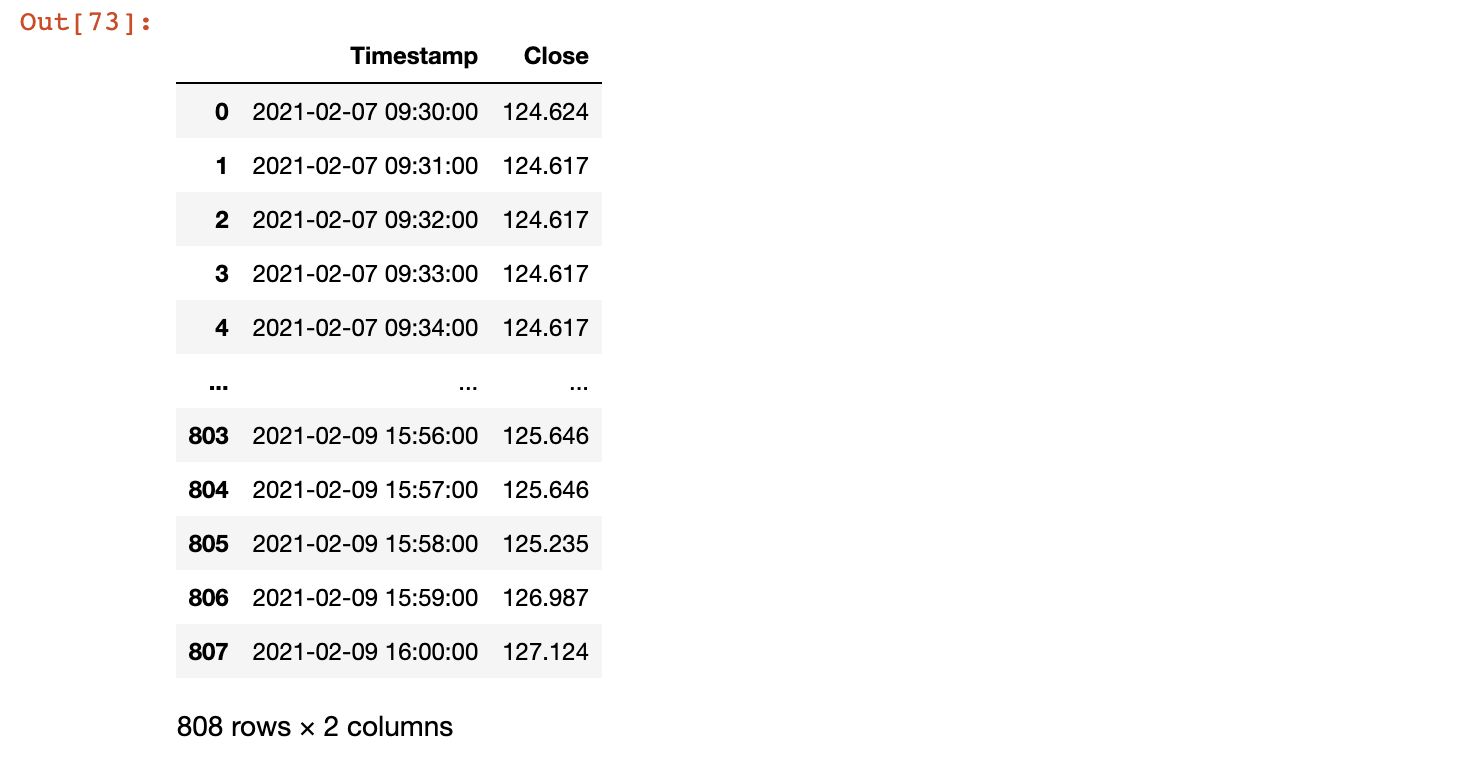
Notice the start (09:30:00) and end (16:00:00) timestamps for the given date.
2. Applying resample over existing dates only
"In the example above it would also generate timestamps on a minute basis for 2021-02-08. How can I avoid this?"
As in the above solution, you can apply the resampling method over date groups separately. In this case, I apply the method using a lambda function after separating out the date from the timestamps. So the resample happens only for the date that exist in the dataset
df_new.Timestamp.dt.date.unique()
array([datetime.date(2021, 2, 7), datetime.date(2021, 2, 9)], dtype=object)
Notice, that the output only contains the 2 unique dates from the original dataset.