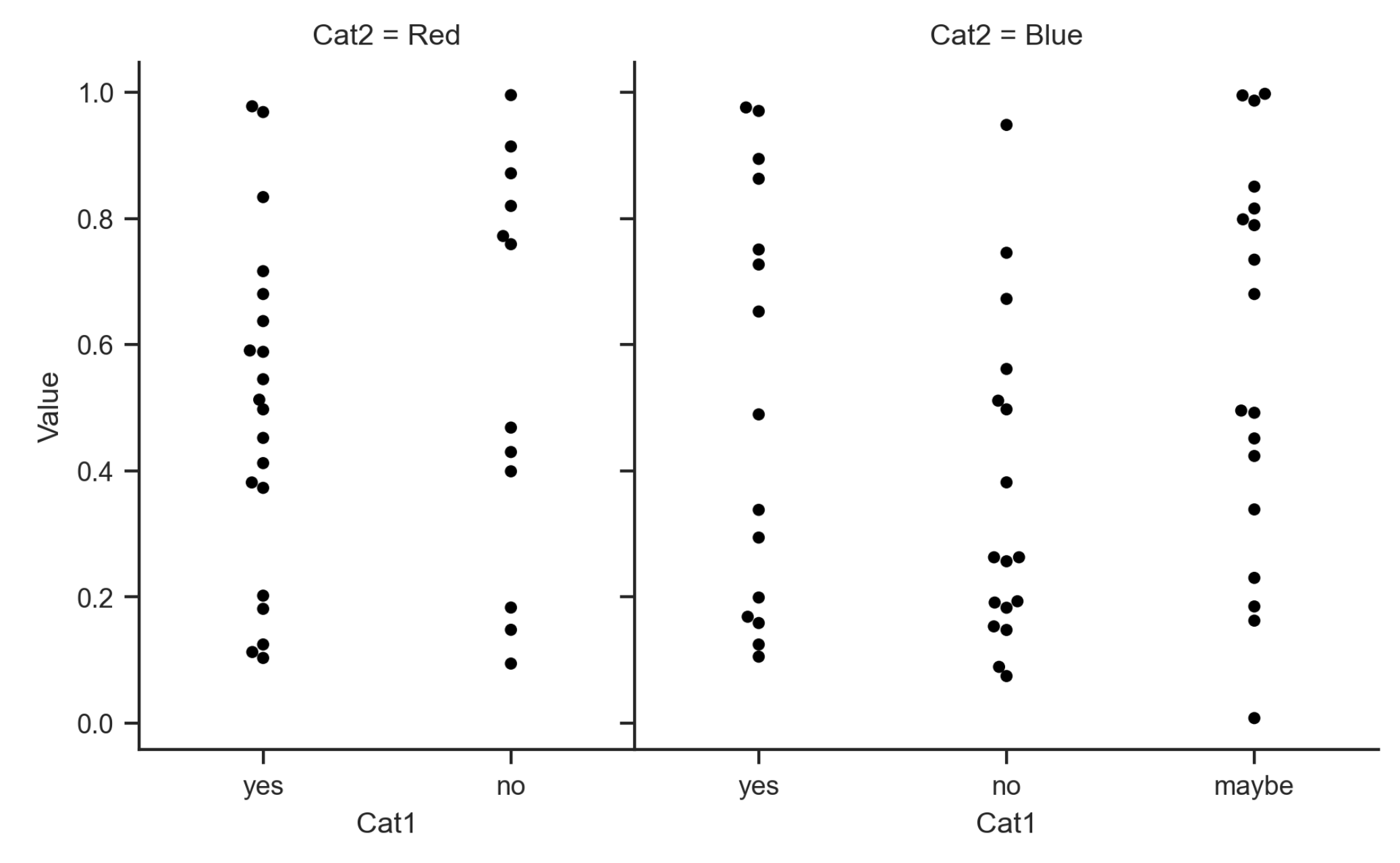
I'm trying to remove one xticks (one column on a categorical axis) from a Seaborn FacetGrid plot. I'm not sure either how to keep the spacing between each tick similar between subplots.
A picture is worth a thousand words, see pictures below:
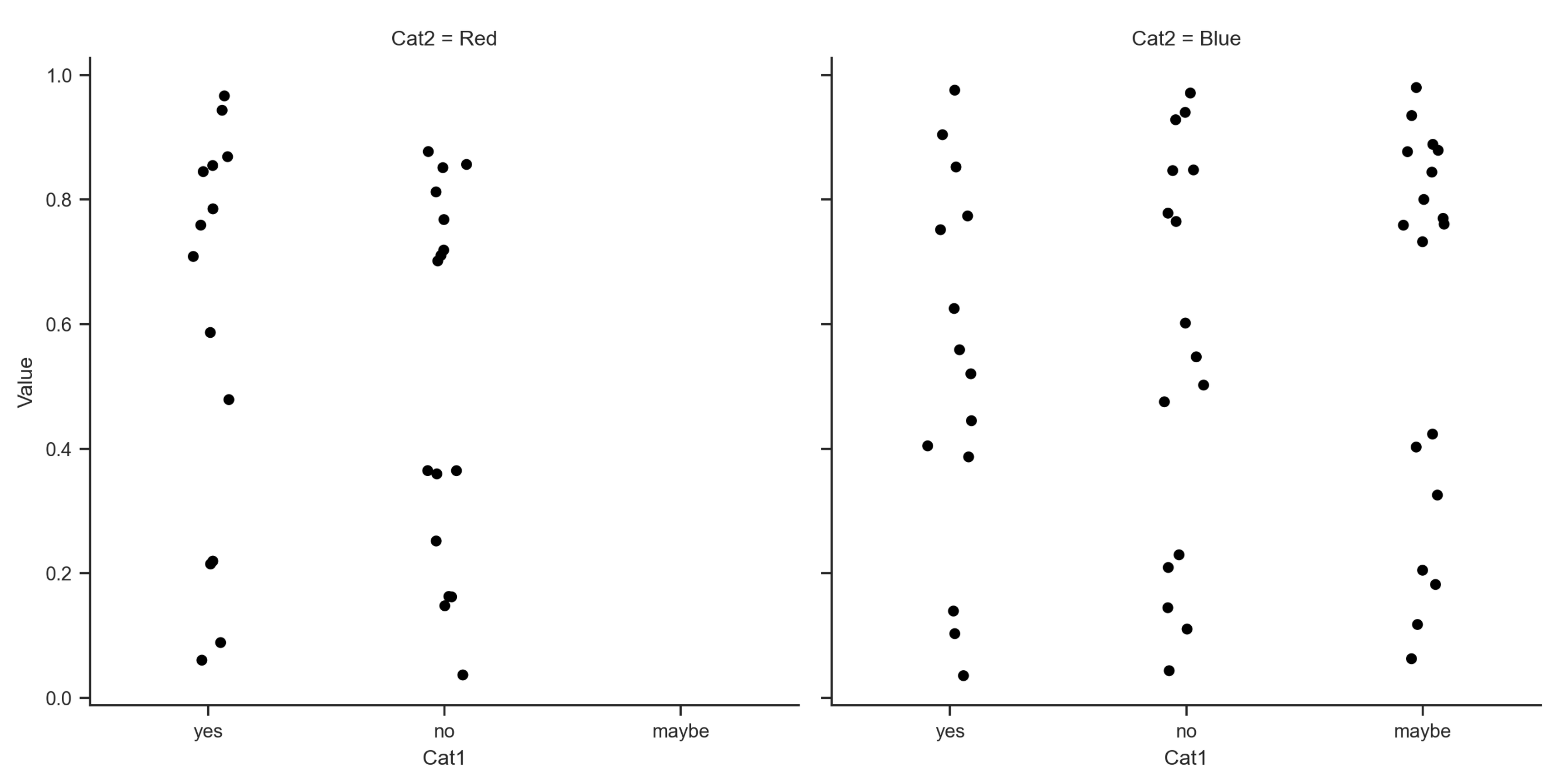 The ideal output would be:
The ideal output would be:
# Testing code
df = pd.DataFrame()
df['Value'] = np.random.rand(100)
df['Cat1'] = np.random.choice(['yes', 'no', 'maybe'], 100)
df['Cat2'] = np.random.choice(['Blue', 'Red'], 100)
df = df[~((df.Cat1 == 'maybe') & (df.Cat2 == 'Red'))]
g = sns.catplot(
data=df,
x='Cat1',
y='Value',
col='Cat2',
col_order=['Red', 'Blue'],
order=['yes', 'no', 'maybe'],
sharex=False,
color='black')
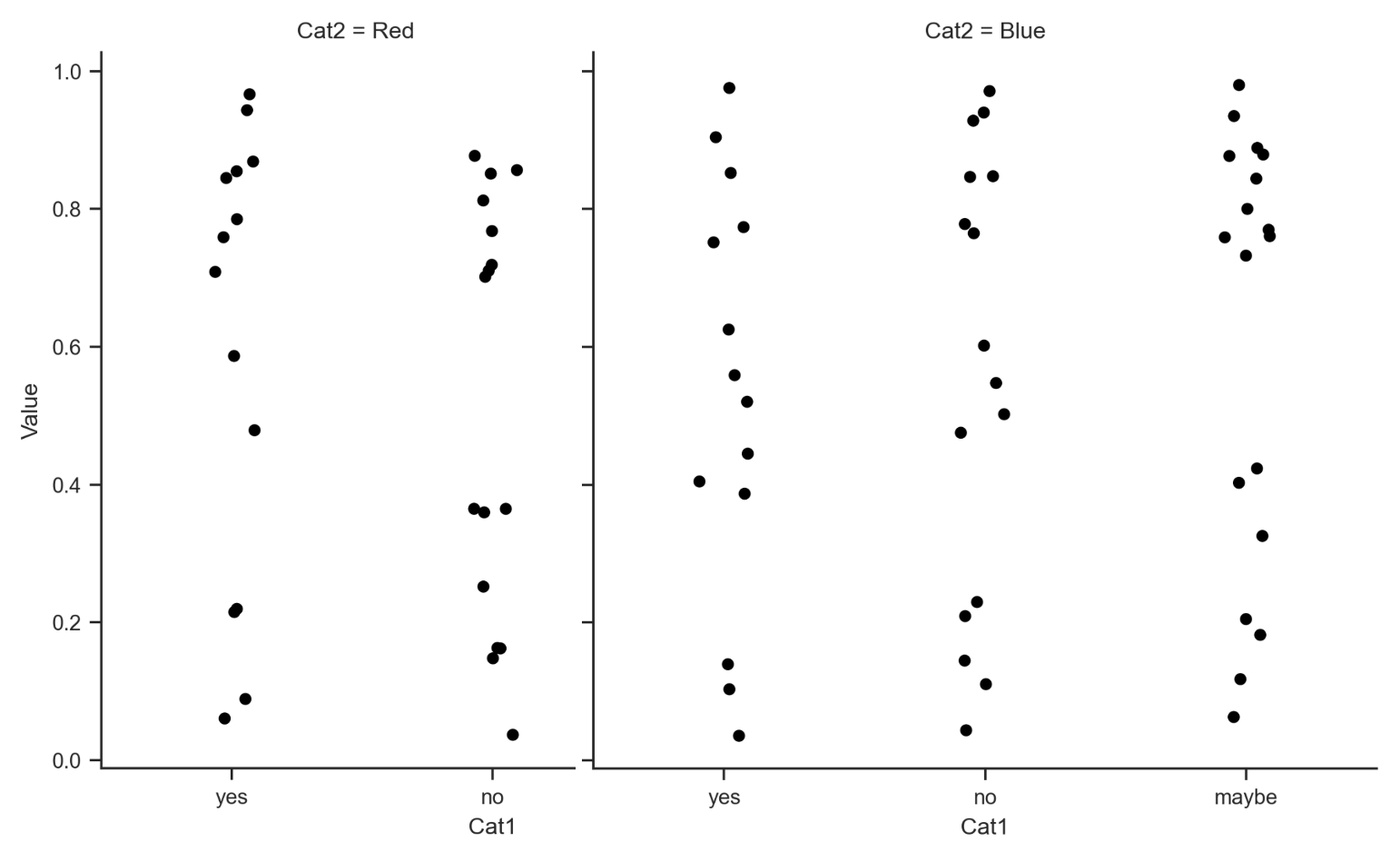
If we don't set the order, it creates a plot like this:
 which has two issues: the order is not set (we want that), and the spacing is awkward.
which has two issues: the order is not set (we want that), and the spacing is awkward.
Any tips? Thanks!
CodePudding user response:
The approach I came up with is to replace the 'maybe' in the tick label of the first subplot with a blank, and move the position of the second subplot to the left, taking the coordinates of the second and subtracting the offset value. For some reason, the height of the second subplot has changed, so I have manually added an adjustment value.
g = sns.catplot(
data=df,
x='Cat1',
y='Value',
col='Cat2',
col_order=['Red', 'Blue'],
order=['yes', 'no', 'maybe'],
sharex=False,
color='black')
labels = g.fig.axes[0].get_xticklabels()
print(labels)
g.fig.axes[0].set_xticklabels(['yes','no',''])
g_pos2 = g.fig.axes[1].get_position()
print(g_pos2)
offset = 0.095
g.fig.axes[1].set_position([g_pos2.x0 - offset, g_pos2.y0, g_pos2.x1 - g_pos2.x0, g_pos2.y1 - 0.11611])
print(g.fig.axes[1].get_position())
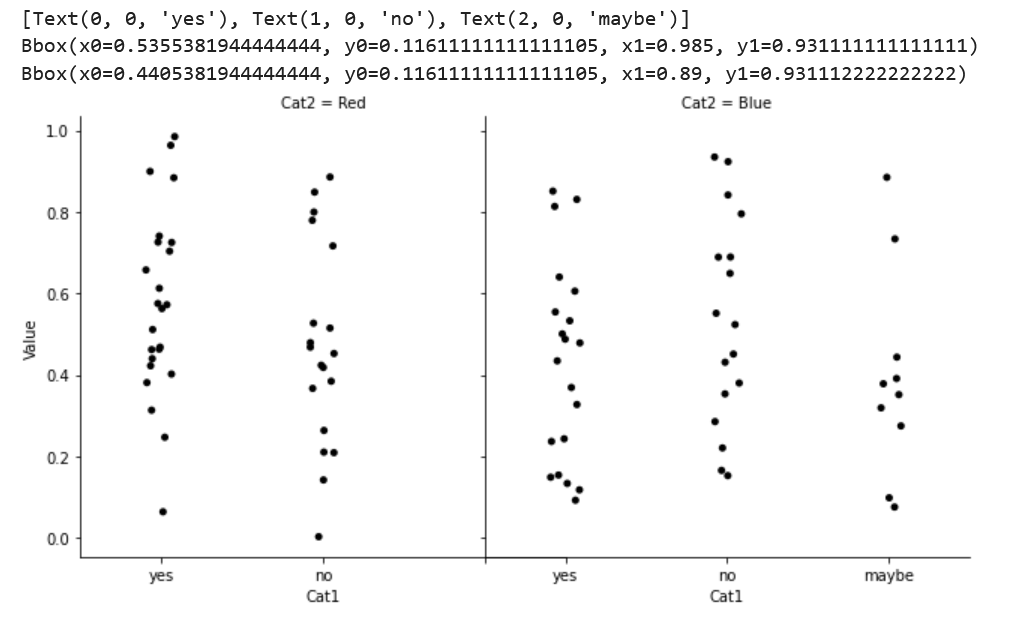
CodePudding user response:
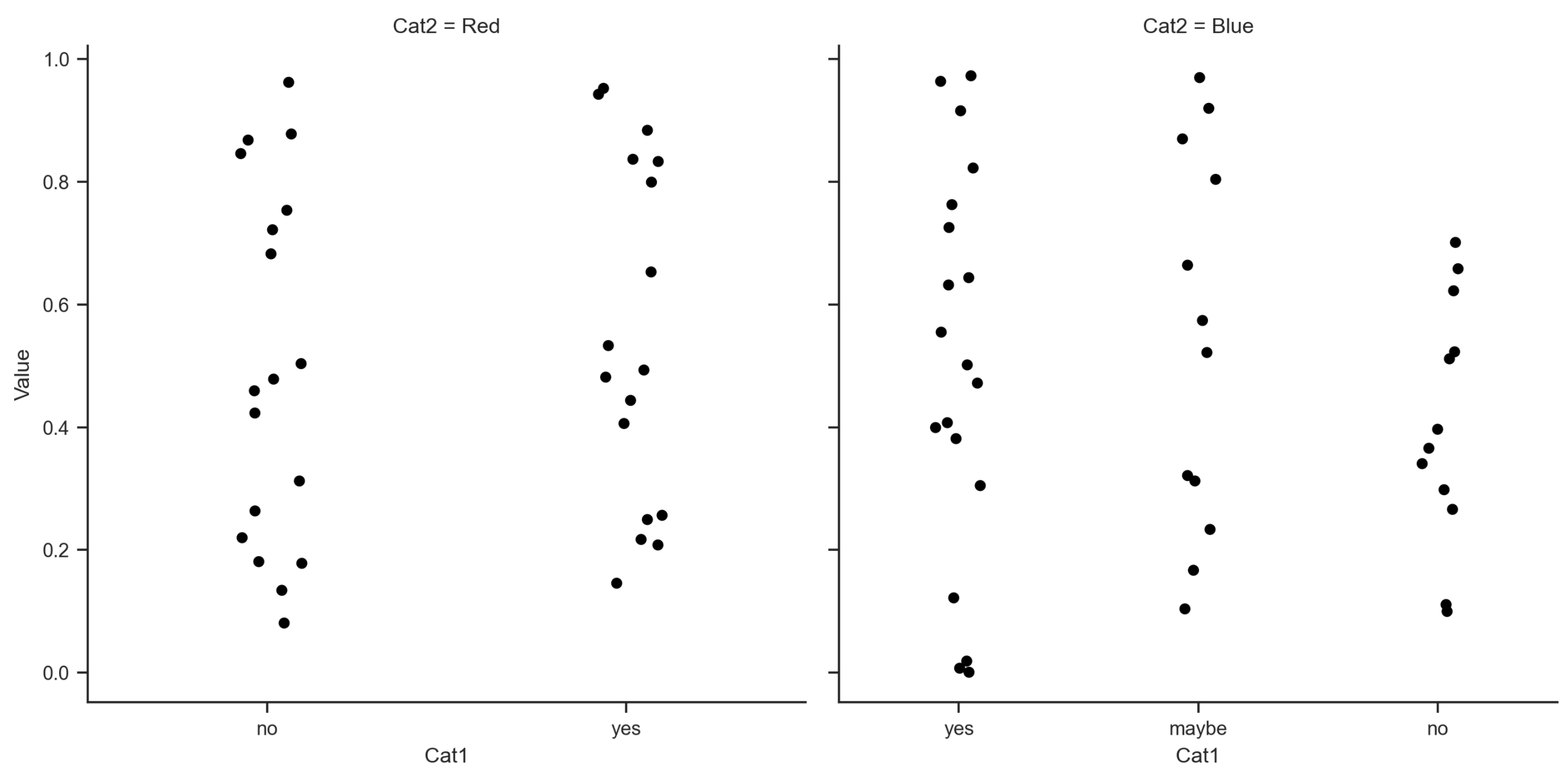
Actually I found a workaround that is more generic than the previous answer.
df = pd.DataFrame()
df['Value'] = np.random.rand(100)
df['Cat1'] = np.random.choice(['yes', 'no', 'maybe'], 100)
df['Cat2'] = np.random.choice(['Blue', 'Red'], 100)
cat_ordered = ['yes', 'no', 'maybe']
# Set to categorical
df.loc[:, 'Cat1'] = df.Cat1.astype('category').cat.set_categories(cat_ordered)
# Reorder dataframe based on the categories (ordered)
df = df.sort_values(by='Cat1')
# Unset the categorical type so that the empty categories don't interfere in plot
df.loc[:, 'Cat1'] = df.Cat1.astype(str)
df = df[~((df.Cat1 == 'maybe') & (df.Cat2 == 'Red'))]
g = sns.FacetGrid(
data=df,
col='Cat2',
col_order=['Red', 'Blue'],
sharex=False, height=4, aspect=0.8,
# use this to squeeze plot to right dimensions
gridspec_kws={'width_ratios': [2, 3]} # easy to parameterize also
)
g.map_dataframe(
sns.swarmplot,
x='Cat1',
y='Value',
color='black', s=4
)
g.fig.subplots_adjust(wspace=0, hspace=0)
Result: