I'm trying to scrape through python, already tried:
- bs4, selenium, requests, helium. [Included classes, tags, xpath, etc]..
Though I never had this kind of issue, maybe I'm doing something wrong. I just can't take this text value: G120-5, shown in the image bellow:
Link: 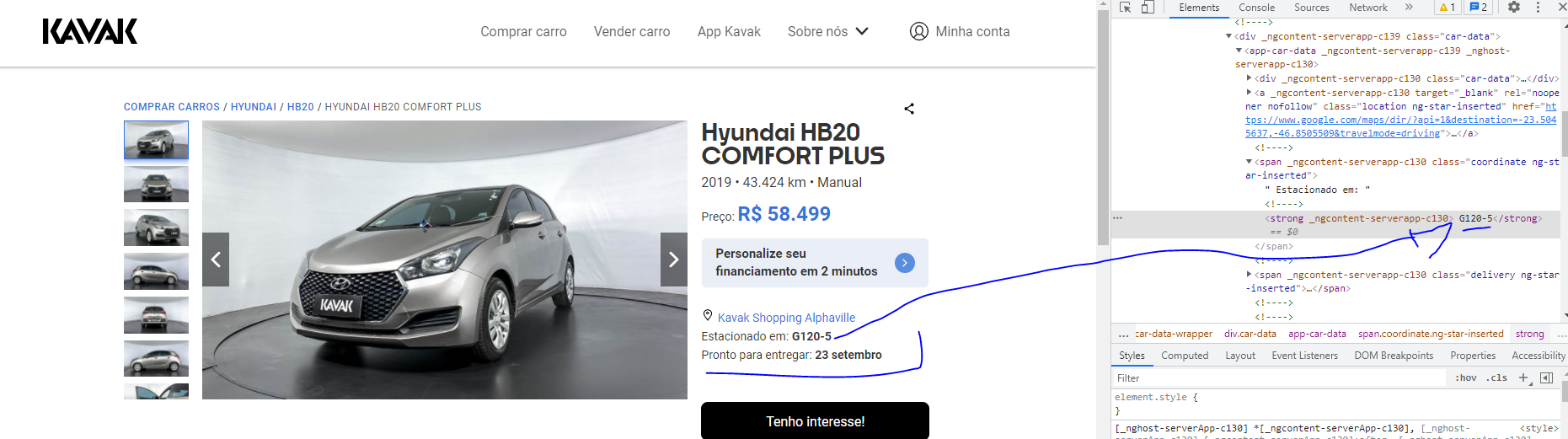
If someone can do it, please let me know. Thanks in advance :)
CodePudding user response:
The data you see is loaded from external URL. You can use requests module to simulate it:
import json
import requests
# url = "https://www.kavak.com/br/carros-usados-100550"
car_id = "100550" # <-- this is the id from URL
api_url = (
f"https://api.kavak.services/services-common/inventory/{car_id}/dynamic"
)
headers = {
"kavak-country-id": "76",
"kavak-region-id": "4",
"kavak-subsidiary-id": "3",
}
data = requests.get(api_url, headers=headers).json()
# uncomment to print all data:
# print(json.dumps(data, indent=4))
print(data["data"]["coordinate"])
Prints:
G120-5