In the dataframe below
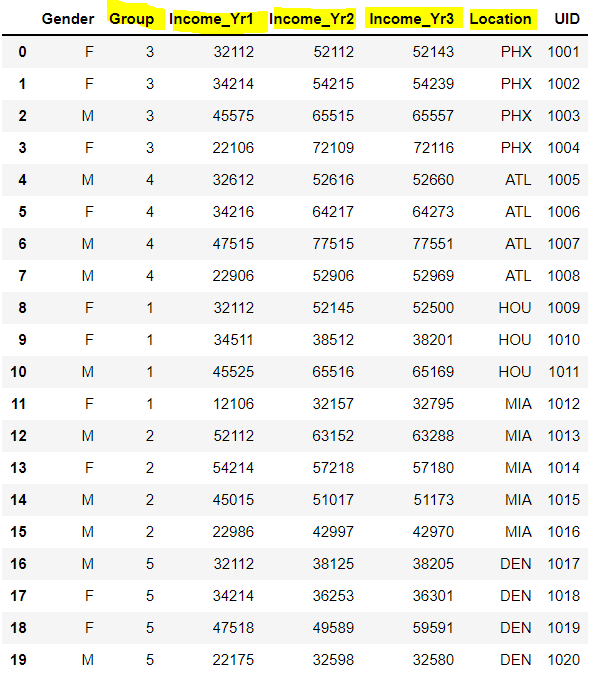
I want to write a def function that takes in a data frame and does the following :
select
Location,Group,Income_Yr1:Income_Yr3columnssort the dataframe using the
Groupcolumn fromlowestto thehighestvaluecreate a pivot table for
mean,medianandstandard deviation( making it 3 tables perIncome_Yror possibly combine them as one ) forIncome_Yr1,Income_Yr2andIncome_Yr3
# DataFrame using arrays.
import pandas as pd
import numpy as np
# initialise data of lists.
data = {'Gender':['F', 'F', 'M', 'F','M', 'F', 'M', 'M','F', 'F', 'M', 'F','M', 'F', 'M', 'M','M','F', 'F', 'M'],
'UID':[1001,1002,1003,1004,1005,1006,1007,1008,1009,1010,1011,1012,1013,1014,1015,1016,1017,1018,1019,1020],
'Location':['PHX','PHX','PHX','PHX','ATL','ATL','ATL','ATL','HOU','HOU','HOU','MIA','MIA','MIA','MIA','MIA','DEN','DEN','DEN','DEN'],
'Group':[3,3,3,3,4,4,4,4,1,1,1,1,2,2,2,2,5,5,5,5],
'Income_Yr1':[32112,34214,45575,22106,32612,34216,47515,22906,32112,34511,45525,12106,52112,54214,45015,22986,32112,34214,47518,22175],
'Income_Yr2':[52112,54215,65515,72109,52616,64217,77515,52906,52145,38512,65516,32157,63152,57218,51017,42997,38125,36253,49589,32598],
'Income_Yr3':[52143,54239,65557,72116,52660,64273,77551,52969,52500,38201,65169,32795,63288,57180,51173,42970,38205,36301,59591,32580]}
df = pd.DataFrame(data)
See below for my attempt, I am open to other approaches
# read in the dataset
def pivot_table (data):
#1. import dataset and select the desired columns, I want to include all column names with string 'Income'
df1 = df[['Group','Location','Income_Yr1':'Income_Yr3']]
#2 sort the data using 'Group' column
df1 = df1.sort_values('Group')
#3a create pivot table for mean
pd.pivot_table(df1,index = ['Group','Location'],values ='Income_Yr1',columns = 'Location',margins = True)
#3b create pivot table for median
pd.pivot_table(df1,index = ['Group','Location'],values ='Income_Yr1',columns = 'Location',aggfunc = 'median', margins = True)
#3c create pivot table for std
pd.pivot_table(df1,index = ['Group','Location'],values ='Income_Yr1',columns = 'Location',aggfunc = np.std, margins = True)
#3d Income_Yr2: create pivot table for mean
pd.pivot_table(df1,index = ['Group','Location'],values ='Income_Yr2',columns = 'Location',margins = True)
#3e Income_Yr2: create pivot table for median
pd.pivot_table(df1,index = ['Group','Location'],values ='Income_Yr2',columns = 'Location',aggfunc = 'median', margins = True)
#3f Income_Yr2 create pivot table for std
pd.pivot_table(df1,index = ['Group','Location'],values ='Income_Yr2',columns = 'Location',aggfunc = np.std, margins = True)
#3g Income_Yr3: create pivot table for mean
pd.pivot_table(df1,index = ['Group','Location'],values ='Income_Yr3',columns = 'Location',margins = True)
#3h Income_Yr3: create pivot table for median
pd.pivot_table(df1,index = ['Group','Location'],values ='Income_Yr3',columns = 'Location',aggfunc = 'median', margins = True)
#3i Income_Yr3 create pivot table for std
pd.pivot_table(df1,index = ['Group','Location'],values ='Income_Yr3',columns = 'Location',aggfunc = np.std, margins = True)
##########
#test code
pivot_table(df)
Thanks
CodePudding user response:
Let's use melt then groupby
We can use a dictionary comprehension then to sort and split your dataframes.
df1 = pd.melt(df,
id_vars=['Group','Location'],
value_vars=df.filter(like='Income').columns.tolist()
).sort_values('value') # default is lowest to highest.
df2 = df1.groupby(['Group','Location','variable'])['value'].agg(['mean','median','std'])
#now for your split dataframes.
out = {income_yr : frame for income_yr, frame in df2.groupby(level=-1)}
print(out['Income_Yr2'])
mean median std
Group Location variable
1 HOU Income_Yr2 52057.666667 52145.0 13502.211831
MIA Income_Yr2 32157.000000 32157.0 NaN
2 MIA Income_Yr2 53596.000000 54117.5 8629.910428
3 PHX Income_Yr2 60987.750000 59865.0 9466.207878
4 ATL Income_Yr2 61813.500000 58561.5 11779.239888
5 DEN Income_Yr2 39141.250000 37189.0 7333.583770
Function
Not sure of the benefit of a function here unless you have very complicated data pipelines or need to re-use this piece of code in many places but this should work,
import pandas as pd
from typing import Dict
def transform_and_split_data(data: pd.DataFrame) -> Dict[str,pd.DataFrame]:
df1 = pd.melt(data,
id_vars=['Group','Location'],
value_vars=data.filter(like='Income').columns.tolist()
).sort_values('value') # default is lowest to highest.
df2 = df1.groupby(['Group','Location','variable'])['value'].agg(['mean','median','std'])
return {income_yr : frame for income_yr, frame in df2.groupby(level=-1)}