How can I enumerate rows in a pandas dataframe based on a condition?
In this example i want to enumerate all rows where column "Check" = "True". So row 2 and 3 should be enumerated with 1 and row 9 to 23 should be enumerated with 2.
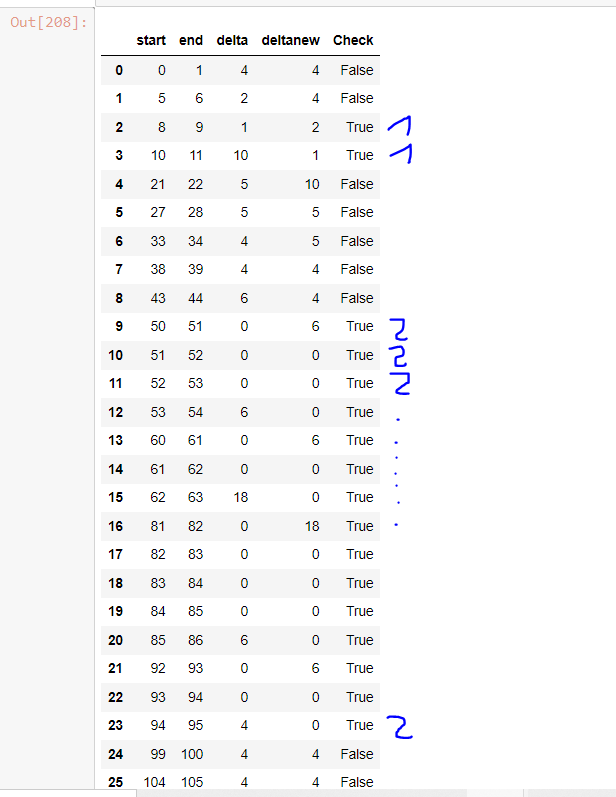
Thank you very much for your ideas!
CodePudding user response:
Let's say we had the following dataframe:
>>> df
data check
0 3588408447395168256 False
1 3611346577085431808 True
2 749264861627678720 True
3 8639996896158416896 False
4 2566054320101392384 False
5 2206545325982744576 True
6 1391007265699397632 True
7 1445594781760618496 True
8 9025069881367724032 False
df['check'].diff() gives us whether each value in the check column differs from the previous one. .ne(False) gives us the ones that do not differ. .cumsum() then gives us a sequentially increasing values we can use to group the rows with:
groups = list(df.groupby(df['check'].diff().ne(False).cumsum()))
This gives us a list of tuples of type (int, DataFrame):
1:
data check
0 3588408447395168256 False
2:
data check
1 3611346577085431808 True
2 749264861627678720 True
3:
data check
3 8639996896158416896 False
4 2566054320101392384 False
4:
data check
5 2206545325982744576 True
6 1391007265699397632 True
7 1445594781760618496 True
5:
data check
8 9025069881367724032 False
You can get every one where check is True by taking every second element, either starting at 0 or 1 depending on what the value of check in the first group is:
groups[not groups[0][1]['check'][0]::2]
Then if you want to re-enumerate them with indices that only count the groups where check is True, you can do like with Python's built-in enumerate function:
enumerate(x[1] for x in groups[not groups[0][1]['check'][0]::2])
CodePudding user response:
I made pdrle package that can help with this. Basically, you identify runs of identical values and use the length of those runs to assign id.
import pdrle
df
# data check
# 0 3588408447395168256 False
# 1 3611346577085431808 True
# 2 749264861627678720 True
# 3 8639996896158416896 False
# 4 2566054320101392384 False
# 5 2206545325982744576 True
# 6 1391007265699397632 True
# 7 1445594781760618496 True
# 8 9025069881367724032 False
rle = pdrle.encode(df.check)
rle
# vals runs
# check
# 0 False 1
# 1 True 2
# 2 False 2
# 3 True 3
# 4 False 1
df["rleid"] = rle.vals.cumsum().repeat(rle.runs).reset_index(drop=True) * df.check
df
# data check rleid
# 0 3588408447395168256 False 0
# 1 3611346577085431808 True 1
# 2 749264861627678720 True 1
# 3 8639996896158416896 False 0
# 4 2566054320101392384 False 0
# 5 2206545325982744576 True 2
# 6 1391007265699397632 True 2
# 7 1445594781760618496 True 2
# 8 9025069881367724032 False 0