I have such a dataframe, after grouping my main one by Pattern and taking the mean of all values:
df_survey = df.groupby(["Pattern"]).mean()
>>>
Pattern Subject Q1 Q2 Q3 Q4 Q5
1.0 1.5 4.5 4.0 1.0 1.5 1.0
3.0 1.5 4.0 4.0 4.0 4.0 5.0
7.0 1.5 5.0 4.0 1.5 1.5 1.5
From there, I would like to plot a graph showing the value of each question (numbered from 1 to 5), per question on the x axis, and with a different hue per Pattern, while leaving alone the Subject part, like so:
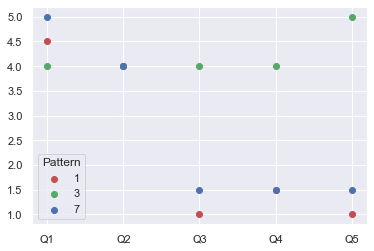
I have tried a lot of different things, using seaborn, matplotlib, using replies from other such questions, etc., and the only thing that worked for me was to pretty much manually put every value in the graph independently, like so:
df_survey = df.groupby(["Pattern"]).mean()
cmap = {1:'r', 3:'g', 7:'b'}
for key, row in df_survey.iterrows():
plt.scatter(x=1, y=df_survey.Q1[key], c=cmap[key], label=int(key))
plt.scatter(x=2, y=df_survey.Q2[key], c=cmap[key])
plt.scatter(x=3, y=df_survey.Q3[key], c=cmap[key])
plt.scatter(x=4, y=df_survey.Q4[key], c=cmap[key])
plt.scatter(x=5, y=df_survey.Q5[key], c=cmap[key])
plt.legend(title="Pattern")
plt.xticks(np.arange(1,6), ['Q1', 'Q2', 'Q3', 'Q4', 'Q5'])
plt.show()
So, I was wondering if there would be an easier and more elegant way to do it. For instance, if the number of questions would be way higher than only 5 it would be more complicated to just put the values manually like that... Also, maybe to have a way to show every dot if they are superposed, like for Q2?
CodePudding user response:
You can use seaborn's 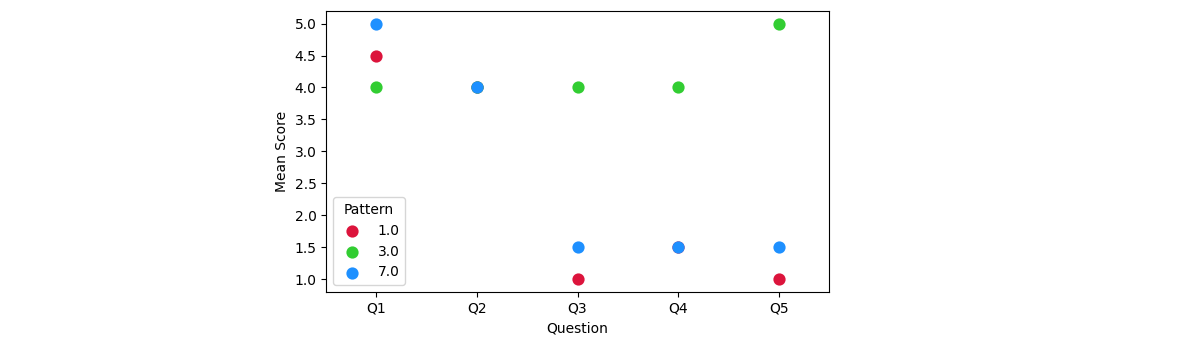
PS: The long form of the dataframe looks like:
Pattern Subject Question Mean Score
0 1.0 1.5 Q1 4.5
1 3.0 1.5 Q1 4.0
2 7.0 1.5 Q1 5.0
3 1.0 1.5 Q2 4.0
4 3.0 1.5 Q2 4.0
5 7.0 1.5 Q2 4.0
6 1.0 1.5 Q3 1.0
...