I am trying to find an object that is downloaded into the browser during the loading of a website.
This is the website, 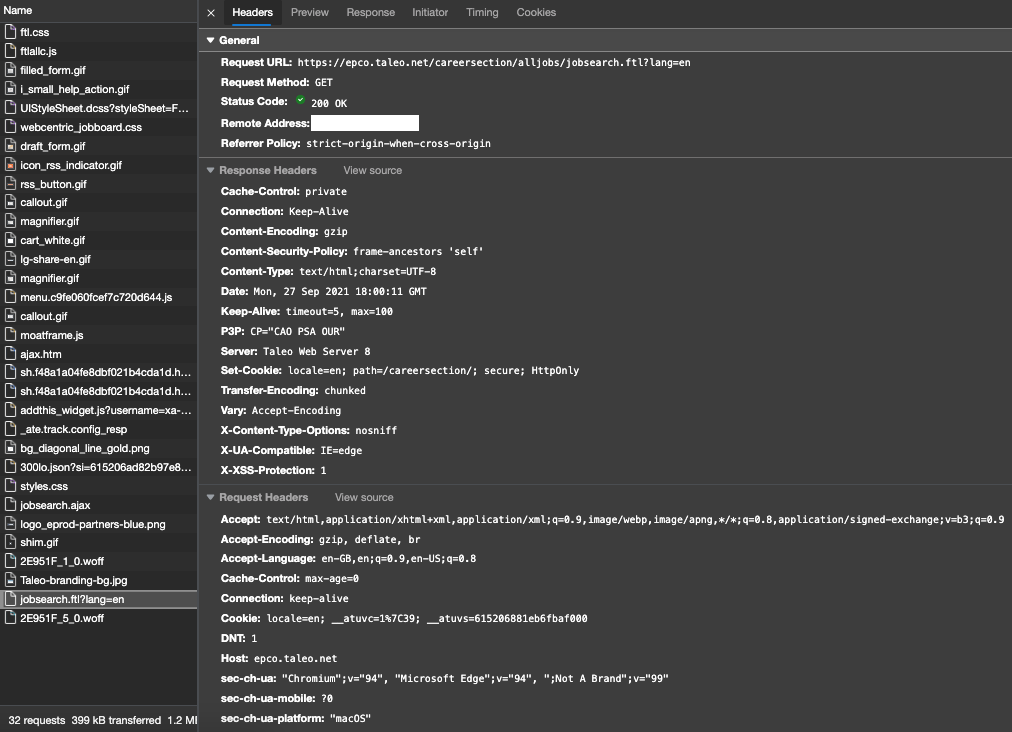
And the reponse.
These are the objects that I want to save. How can I do that?
I have tried
import json
from selenium import webdriver
from selenium.webdriver.common.desired_capabilities import DesiredCapabilities
from selenium.webdriver.common.by import By
from selenium.common.exceptions import NoSuchElementException, TimeoutException, StaleElementReferenceException
from selenium.webdriver.support.ui import WebDriverWait
from selenium.webdriver.support import expected_conditions as EC
from selenium.webdriver.chrome.options import Options
chromepath = "~/chromedriver/chromedriver"
caps = DesiredCapabilities.CHROME
caps['goog:loggingPrefs'] = {'performance': 'ALL'}
driver = webdriver.Chrome(executable_path=chromepath, desired_capabilities=caps)
driver.get('https://epco.taleo.net/careersection/alljobs/jobsearch.ftl?lang=en')
def process_browser_log_entry(entry):
response = json.loads(entry['message'])['message']
return response
browser_log = driver.get_log('performance')
events = [process_browser_log_entry(entry) for entry in browser_log]
events = [event for event in events if 'Network.response' in event['method']]
But I only get some of the headers, they look like this,
{'method': 'Network.responseReceivedExtraInfo',
'params': {'blockedCookies': [],
'headers': {'Cache-Control': 'private',
'Connection': 'Keep-Alive',
'Content-Encoding': 'gzip',
'Content-Security-Policy': "frame-ancestors 'self'",
'Content-Type': 'text/html;charset=UTF-8',
'Date': 'Mon, 27 Sep 2021 18:18:10 GMT',
'Keep-Alive': 'timeout=5, max=100',
'P3P': 'CP="CAO PSA OUR"',
'Server': 'Taleo Web Server 8',
'Set-Cookie': 'locale=en; path=/careersection/; secure; HttpOnly',
'Transfer-Encoding': 'chunked',
'Vary': 'Accept-Encoding',
'X-Content-Type-Options': 'nosniff',
'X-UA-Compatible': 'IE=edge',
'X-XSS-Protection': '1'},
'headersText': 'HTTP/1.1 200 OK\r\nDate: Mon, 27 Sep 2021 18:18:10 GMT\r\nServer: Taleo Web Server 8\r\nCache-Control: private\r\nP3P: CP="CAO PSA OUR"\r\nContent-Encoding: gzip\r\nVary: Accept-Encoding\r\nX-Content-Type-Options: nosniff\r\nSet-Cookie: locale=en; path=/careersection/; secure; HttpOnly\r\nContent-Security-Policy: frame-ancestors \'self\'\r\nX-XSS-Protection: 1\r\nX-UA-Compatible: IE=edge\r\nKeep-Alive: timeout=5, max=100\r\nConnection: Keep-Alive\r\nTransfer-Encoding: chunked\r\nContent-Type: text/html;charset=UTF-8\r\n\r\n',
'requestId': '1E3CDDE80EE37825EF2D9C909FFFAFF3',
'resourceIPAddressSpace': 'Public'}},
{'method': 'Network.responseReceived',
'params': {'frameId': '1624E6F3E724CA508A6D55D556CBE198',
'loaderId': '1E3CDDE80EE37825EF2D9C909FFFAFF3',
'requestId': '1E3CDDE80EE37825EF2D9C909FFFAFF3',
'response': {'connectionId': 26,
They don't contain all the information I can see from the web inspector in chrome.
I want to get the whole response and request headers and the actual response. Is this the correct way? Is there another better way which doesn't use selenium and only requests instead?
CodePudding user response:
You can use the selenium-wire library if you want to use Selenium to work with this. However, if you're only concerned for a specific API, then rather than using Selenium, you can use the requests library for hitting the API and then print the results of the request and response headers.
Considering you're looking for the earlier, using the Selenium way, one way to achieve this is using selenium-wire library. However, it will give the result for all the background API's/requests being hit - which you can then easily filter after either piping the result to a text file or in terminal itself
Install using pip install selenium-wire
Install webdriver-manager using pip install webdriver-manager
Install Selenium 4 using pip install selenium==4.0.0.b4
Use this code
from seleniumwire import webdriver
from webdriver_manager.chrome import ChromeDriverManager
from selenium.webdriver.chrome.service import Service
svc= Service(ChromeDriverManager().install())
driver = webdriver.Chrome(service=svc)
driver.maximize_window()
# To use firefox browser
driver.get("https://epco.taleo.net/careersection/alljobs/jobsearch.ftl?lang=en")
for request in driver.requests:
if request.response:
print(
request.url,
request.response.status_code,
request.headers,
request.response.headers
)
which gives a detailed output of all the requests - copying the relavent one -
https://epco.taleo.net/careersection/alljobs/jobsearch.ftl?lang=en 200
Host: epco.taleo.net
Connection: keep-alive
sec-ch-ua: "Chromium";v="94", "Google Chrome";v="94", ";Not A Brand";v="99"
sec-ch-ua-mobile: ?0
sec-ch-ua-platform: "macOS"
Upgrade-Insecure-Requests: 1
User-Agent: Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_7) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/94.0.4606.61 Safari/537.36
Accept: text/html,application/xhtml xml,application/xml;q=0.9,image/avif,image/webp,image/apng,*/*;q=0.8,application/signed-exchange;v=b3;q=0.9
Sec-Fetch-Site: none
Sec-Fetch-Mode: navigate
Sec-Fetch-User: ?1
Sec-Fetch-Dest: document
Accept-Encoding: gzip, deflate, br
Accept-Language: en-GB,en-US;q=0.9,en;q=0.8
Date: Tue, 28 Sep 2021 11:14:14 GMT
Server: Taleo Web Server 8
Cache-Control: private
P3P: CP="CAO PSA OUR"
Content-Encoding: gzip
Vary: Accept-Encoding
X-Content-Type-Options: nosniff
Set-Cookie: locale=en; path=/careersection/; secure; HttpOnly
Content-Security-Policy: frame-ancestors 'self'
X-XSS-Protection: 1
X-UA-Compatible: IE=edge
Keep-Alive: timeout=5, max=100
Connection: Keep-Alive
Transfer-Encoding: chunked
Content-Type: text/html;charset=UTF-8
CodePudding user response:
You can use JS in selenium. So this will be easier:
var req = new XmlHttpRequest();
req.open("get", url_address_string);
req.send();
// when you get your data then:
x.getAllResponseHeaders();
XmlHttpRequest is async, so you need some code to consume answer.
Ok here you go:
from selenium import webdriver
import time
driver = webdriver.Chrome()
driver.get("https://stackoverflow.com")
headers = driver.execute_script(""" var xhr = new XMLHttpRequest();
var rH;
xhr.addEventListener('loadend', (ev) => {
window.rH = xhr.getAllResponseHeaders(); // <-- we assing headers to proprty in window object so then we can use it
console.log(rH);
return rH;
})
xhr.open("get", "https://stackoverflow.com/")
xhr.send()
""")
# need to wait bcoz xhr request is async, this is dirty don't do this ;)
time.sleep(5)
# and we now can extract our 'rH' property from window. With javascript
headers = driver.execute_script("""return window.rH""")
# <--- "accept-ranges: bytes\r\ncache-control: private\r\ncontent-encoding: gzip\r\ncontent-security-policy: upgrade-insecure-requests; ....
print(headers)
# headers arejust string but parts of it are separated with \r\n so you need to
# headers.split("\r\n")
# then you will find a list