Im trying to scrape the 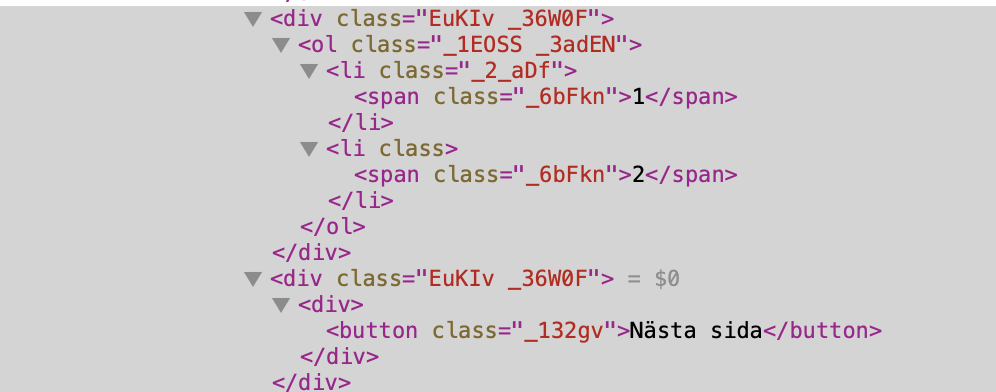
In other tutorials, they could find the href link to the next-button by finding looping over the links in the webpage. When I do this, I get only the main links for the site (despite loading a nested url) and not find any next button.
nav = soup.nav
for url in nav.find_all('a'):
print(url.get('href'))
Do you have any ideas on how to access the url of the next-button in this case?
CodePudding user response:
I'm not very familiar with all options of Beautiful soup in particular, but most likely that assumes there is a href in the link you are about to click, so this will not work. The page seems to be a SPA, maybe this next button is implemented with some java script (event listener for example) that requests data and updates the page.
It seems like most of the data is loaded in via API call to https://www.booli.se/graphql (see network). With parameters such as query, variables etc. in the request body:
{
"operationName": "searchForSale",
"variables": {
"input": {
"page": 2,
"filters": [
{
"key": "objectType",
"value": "Lägenhet,Parhus,Radhus,Kedjehus"
},
{
"key": "rooms",
"value": "3,2,4"
},
{
"key": "minLivingArea",
"value": "60"
}
}
}
Instead of trying to go to the next page, you could send this request directly and use the response data, adapting the variables to your needs (if needed you can increase page here).
CodePudding user response:
You can select any element part of the html tree using CSS and/or XPath selectors.
I kindly link the stack overflow post that goes into detail how to do it in beautiful soup.
TLDR: use from lxml import etree to parse and support XPath
Xpath could be something like
//div/button[@class='_132gv'] or any other specific thing look up XPath syntax
You can always count the number of elements, check presence etc, especially with XPath which supports even much more.