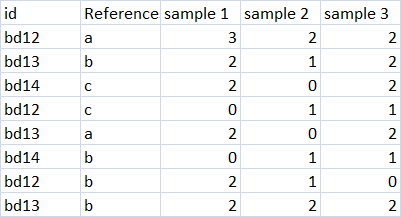
The aim is to get a subset DataFrame such as with three columns after each iteration
'id', 'reference','sample 1' when sample 1 is 0 (do this for every sample)
'id', 'reference','sample 1' when sample 1 is 1 (do this for every sample)
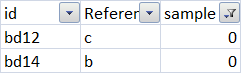
example when sample 1 = 0, the resulting subset DataFrame would be
CodePudding user response:
Try:
sample_cols = df.columns[2:]
dfs = []
for col in sample_cols:
print('='*50, col, '='*50)
for condition in [0, 1]:
print('='*20, condition, '='*20)
df_subset = df[df[col]==condition].reset_index(drop=True)
df_subset = df_subset[['id', 'Reference', col]]
print(df_subset)
#df_subset.to_csv(f'./{col}_{condition}.csv', index=False)
dfs.append(df_subset)
df_final = pd.concat(dfs, ignore_index=True)
df_final.to_csv('./file_name.csv', index=False)