I have the following dataset (of which this is a subset):
structure(list(Session = structure(c(2L, 1L, 1L, 2L, 2L, 2L,
1L, 2L, 2L, 2L, 1L, 1L, 1L, 2L, 2L, 1L, 1L, 1L, 2L, 1L, 2L, 2L,
1L, 2L, 2L, 2L, 2L, 1L, 2L, 2L, 2L, 1L, 1L, 2L, 1L, 1L, 1L, 1L,
2L, 2L, 1L, 1L, 2L, 2L, 1L, 1L, 1L, 1L, 1L, 2L), .Label = c("Pre",
"Post"), class = "factor"), First.Name = c(5019L, 8007L, 5059L,
5037L, 5023L, 6023L, 8029L, 6009L, 7034L, 5011L, 5062L, 8026L,
5019L, 7022L, 7017L, 7002L, 5037L, 5034L, 6005L, 8006L, 6036L,
7011L, 5010L, 5038L, 6049L, 5007L, 5032L, 6016L, 5052L, 8033L,
5026L, 7017L, 8002L, 7014L, 5061L, 7034L, 6018L, 6013L, 5063L,
6016L, 5007L, 6014L, 5059L, 5049L, 7007L, 5024L, 7008L, 6007L,
6041L, 5061L), Age = structure(c(1L, 2L, 1L, 1L, 1L, 1L, 2L,
1L, 2L, 1L, 1L, 2L, 1L, 2L, 2L, 2L, 1L, 1L, 1L, 2L, 1L, 2L, 1L,
1L, 1L, 1L, 1L, 1L, 1L, 2L, 1L, 2L, 2L, 2L, 1L, 2L, 1L, 1L, 1L,
1L, 1L, 1L, 1L, 1L, 2L, 1L, 2L, 1L, 1L, 1L), .Label = c("Young",
"Old"), class = "factor"), Group = c("Increase", "Decrease",
"Increase", "Increase", "Increase", "Decrease", "Decrease", "Decrease",
"Increase", "Increase", "Increase", "Decrease", "Increase", "Increase",
"Increase", "Increase", "Increase", "Increase", "Decrease", "Decrease",
"Decrease", "Increase", "Increase", "Increase", "Decrease", "Increase",
"Increase", "Decrease", "Increase", "Decrease", "Increase", "Increase",
"Decrease", "Increase", "Increase", "Increase", "Decrease", "Decrease",
"Increase", "Decrease", "Increase", "Decrease", "Increase", "Increase",
"Increase", "Increase", "Increase", "Decrease", "Decrease", "Increase"
), RHR = c(52.8421052631579, 63.2857142857143, 63.2, 62.9090909090909,
80.1818181818182, 61.5806451612903, 70, 64.2121212121212, 71.9,
77.3333333333333, 64.75, 58.4, 48.4, 47.0277777777778, 49.9,
63.3333333333333, 59.8571428571429, 54.2, 56.0322580645161, 62.375,
59.8823529411765, 49.0882352941176, 73.4545454545455, 54.4516129032258,
51.84, 62.5882352941176, 69.2307692307692, 53.5555555555556,
52.6296296296296, 58.2608695652174, 58.3333333333333, 52.375,
69, 51.4285714285714, 53.2, 76.125, 54.8571428571429, 59.625,
70.0909090909091, 52.1612903225806, 63, 58.6, 61.8285714285714,
61, 56.3333333333333, 68.3333333333333, 52, 69.9, 63.7142857142857,
56.9428571428571)), row.names = c(NA, -50L), groups = structure(list(
First.Name = c(235007L, 235007L, 235010L, 523011L, 235019L, 235019L,
235023L, 235024L, 235026L, 235032L, 235034L, 235037L, 235037L, 235038L, 235049L,
235052L, 235059L, 235059L, 235061L, 235061L, 235062L, 235063L, 236005L, 236007L,
236009L, 236013L, 236014L, 236016L, 236016L, 236018L, 236023L, 236036L, 236041L,
236049L, 237002L, 237007L, 237008L, 237011L, 237014L, 237017L, 237017L, 237022L,
237034L, 237034L, 238002L, 238006L, 238007L, 238026L, 238029L, 238033L),
Session = structure(c(1L, 2L, 1L, 2L, 1L, 2L, 2L, 1L, 2L,
2L, 1L, 1L, 2L, 2L, 2L, 2L, 1L, 2L, 1L, 2L, 1L, 2L, 2L, 1L,
2L, 1L, 1L, 1L, 2L, 1L, 2L, 2L, 1L, 2L, 1L, 1L, 1L, 2L, 2L,
1L, 2L, 2L, 1L, 2L, 1L, 1L, 1L, 1L, 1L, 2L), .Label = c("Pre",
"Post"), class = "factor"), .rows = structure(list(41L, 26L,
23L, 10L, 13L, 1L, 5L, 46L, 31L, 27L, 18L, 17L, 4L, 24L,
44L, 29L, 3L, 43L, 35L, 50L, 11L, 39L, 19L, 48L, 8L,
38L, 42L, 28L, 40L, 37L, 6L, 21L, 49L, 25L, 16L, 45L,
47L, 22L, 34L, 32L, 15L, 14L, 36L, 9L, 33L, 20L, 2L,
12L, 7L, 30L), ptype = integer(0), class = c("vctrs_list_of",
"vctrs_vctr", "list"))), row.names = c(NA, 50L), class = c("tbl_df",
"tbl", "data.frame"), .drop = TRUE), class = c("grouped_df",
"tbl_df", "tbl", "data.frame"))
Which looks like:
# A tibble: 50 x 5
# Groups: First.Name, Session [50]
Session First.Name Age Group RHR
<fct> <int> <fct> <chr> <dbl>
1 Post 235019 Young Increase 52.8
2 Pre 238007 Old Decrease 63.3
3 Pre 235059 Young Increase 63.2
4 Post 235037 Young Increase 62.9
5 Post 235023 Young Increase 80.2
6 Post 236023 Young Decrease 61.6
7 Pre 238029 Old Decrease 70
8 Post 236009 Young Decrease 64.2
9 Post 237034 Old Increase 71.9
10 Post 235011 Young Increase 77.3
I am trying to annotate some text in my plot with italics and with variables. I can get the plot to show the text when parse = F but the text is not italicized and overlaps on top of each other.
My goal with annotation is to add the ANOVA results to the plot, I originally tried stat_compare_means but could not get an interaction term between session and Group levels so I am taking the long route.
my code is:
## Constants
alpha = .4
se_fun <- function(x) sd(x)/sqrt(length(x))
mean_RHR <- subset(DF, !is.na(Session)) %>%
group_by(Session, Group) %>%
summarise_at(vars(RHR), funs(mean(., na.rm=TRUE)))
mean_RHR$Session <- factor(mean_RHR$Session, levels=c("Pre", "Post"))
#standard error
se_RHR <- se_fun(mean_RHR$RHR)
#statistics
#anova
model_aov <- aov(RHR ~ Session*Group, data = DF)
aov_interaction_p <- summary(model_aov)[[1]][["Pr(>F)"]][3] %>% formatC(format = "f", digits = 3 ) %>% as.character()
#effect size
eta_aov <- effectsize::eta_squared(model_aov)
eta_plot <- eta_aov$Eta2_partial[3] %>% formatC(format = "f", digits = 4 ) %>% as.character()
#cohens d
coh_d <- effsize::cohen.d(RHR ~ Session, paired = T, data = DF)
cohenD_plot <- coh_d$estimate %>% formatC(format = "f", digits = 3 ) %>% as.character()
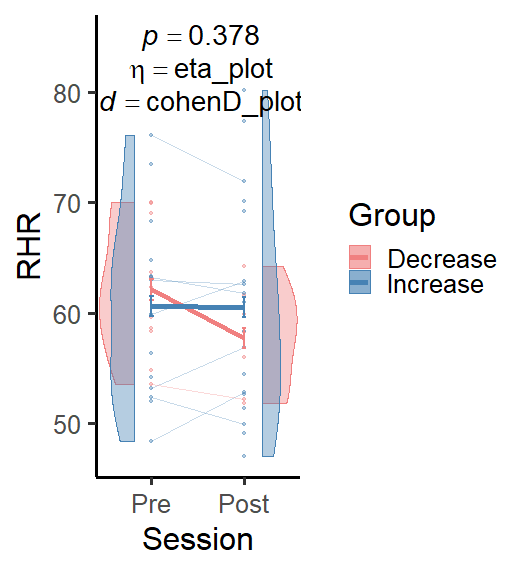
ggplot(data = subset(DF, !is.na(Session)),
aes(x = Session, y = RHR, color = Group))
scale_fill_manual(values = c("lightcoral", "steelblue"))
scale_color_manual(values = c("lightcoral", "steelblue"))
geom_point(size = 1,
alpha = alpha)
geom_line(aes(group = First.Name),
size = .25,
alpha = 0.3)
geom_line(data = mean_RHR, aes(x = Session, y = RHR,
color = Group,
group = Group),
size = 2)
geom_half_violin(aes(fill = Group),
data = DF%>% filter(Session == "Pre"),
alpha = alpha,
side = "l",
position = position_nudge(x = -.19))
geom_half_violin(aes(fill = Group),
data = DF %>% filter(Session == "Post"),
alpha = alpha,
side = "r",
position = position_nudge(x = .19))
geom_errorbar(data = mean_RHR,
aes(x = Session, y = RHR,
ymin = RHR-se_RHR, ymax = RHR se_RHR,
group = Group),
width = 0.05, size = 1)
theme_classic(base_size=24)
annotate("text", x = 1.5, y=85, size = 7.5,
label = c(paste0("italic(p)== ", aov_interaction_p),
paste0("italic(eta)== ", eta_plot),
paste0("italic(d)== ", cohenD_plot)), parse = F)
I see very straightforward ways to italicize the text so I am not sure why I keep getting the error: Error in parse(text = text[[i]]) : <text>:1:19: unexpected symbol 1: italic(p)== 0.756italic
CodePudding user response:
Your code is erroring on eta_plot and cohenD_plot for me but try this.
annotate(
"text",
x = 1.5,
y = c(85, 82, 79),
size = 7.5,
label = c(
paste0("~italic(p)== ", aov_interaction_p),
paste0("~italic(eta)== ", "eta_plot"),
paste0("~italic(d)== ", "cohenD_plot")
),
parse = TRUE
)