I have a table in SQL Server, I've grouped it by ID and created 2 new columns with the counts of other data. I want to be able to create another column at the same time, which displays a 1 if the counts in both columns are greater than a number, otherwise will display 2. However when I try it, it says invalid column name, I guess as my count columns aren't in the original table?
My data is similar to:
ID Data1 Data2
-------------------------
0 1 1 5
1 1 2 5
2 1 5 8
3 1 7 9
4 2 8 5
5 2 7 3
6 2 9 2
7 3 3 1
8 3 3 6
9 3 2 7
10 3 6 3
11 3 8 0
Desired output (where code is 1 if >= 4, else 2):
ID CountData1 CountData2 Code
------------------------------------
0 1 4 4 1
1 2 3 3 2
2 3 5 5 1
Current query:
SELECT
ID,
COUNT(Data1) AS CountData1,
COUNT(Data2) AS CountData2,
(CASE WHEN (CountData1 >= 4 and CountData2 >= 4) THEN 1 ELSE 2 END) AS Code
FROM
Table
GROUP BY
ID
CodePudding user response:
The way that SQL statements are parsed, you cannot reference an expression you just created at the same scope.
You can either repeat the expressions again:
SELECT
ID,
COUNT(Data1) AS CountData1,
COUNT(Data2) AS CountData2,
(CASE WHEN (COUNT(Data1) >= 4 and COUNT(Data2) >= 4) THEN 1 ELSE 2 END)
AS Code
FROM
dbo.Table
GROUP BY
ID;
Or use a CTE or derived table:
-- CTE
;WITH cte AS
(
SELECT ID,
COUNT(Data1) AS CountData1,
COUNT(Data2) AS CountData2
FROM dbo.Table
GROUP BY ID
)
SELECT ID, CountData1, CountData2,
CASE WHEN CountData1 >= 4 AND CountData2 >- 4
THEN 1 ELSE 2 END AS Code
FROM cte;
-- Derived Table
SELECT ID, CountData1, CountData2,
CASE WHEN CountData1 >= 4 AND CountData2 >- 4
THEN 1 ELSE 2 END AS Code
FROM
(
SELECT ID,
COUNT(Data1) AS CountData1,
COUNT(Data2) AS CountData2
FROM dbo.Table
GROUP BY ID
) AS DerivedTable;
These all perform the same, in spite of some folks who believe the first one is worse because you reference COUNT() additional times. SQL Server is pretty good about not repeating work it doesn't have to, and in fact all three queries above yield the exact same execution plan, with the exact same cost, same number of reads, the same output, and the exact same number of expressions are calculated. CPU and duration will vary slightly because, well, computers.
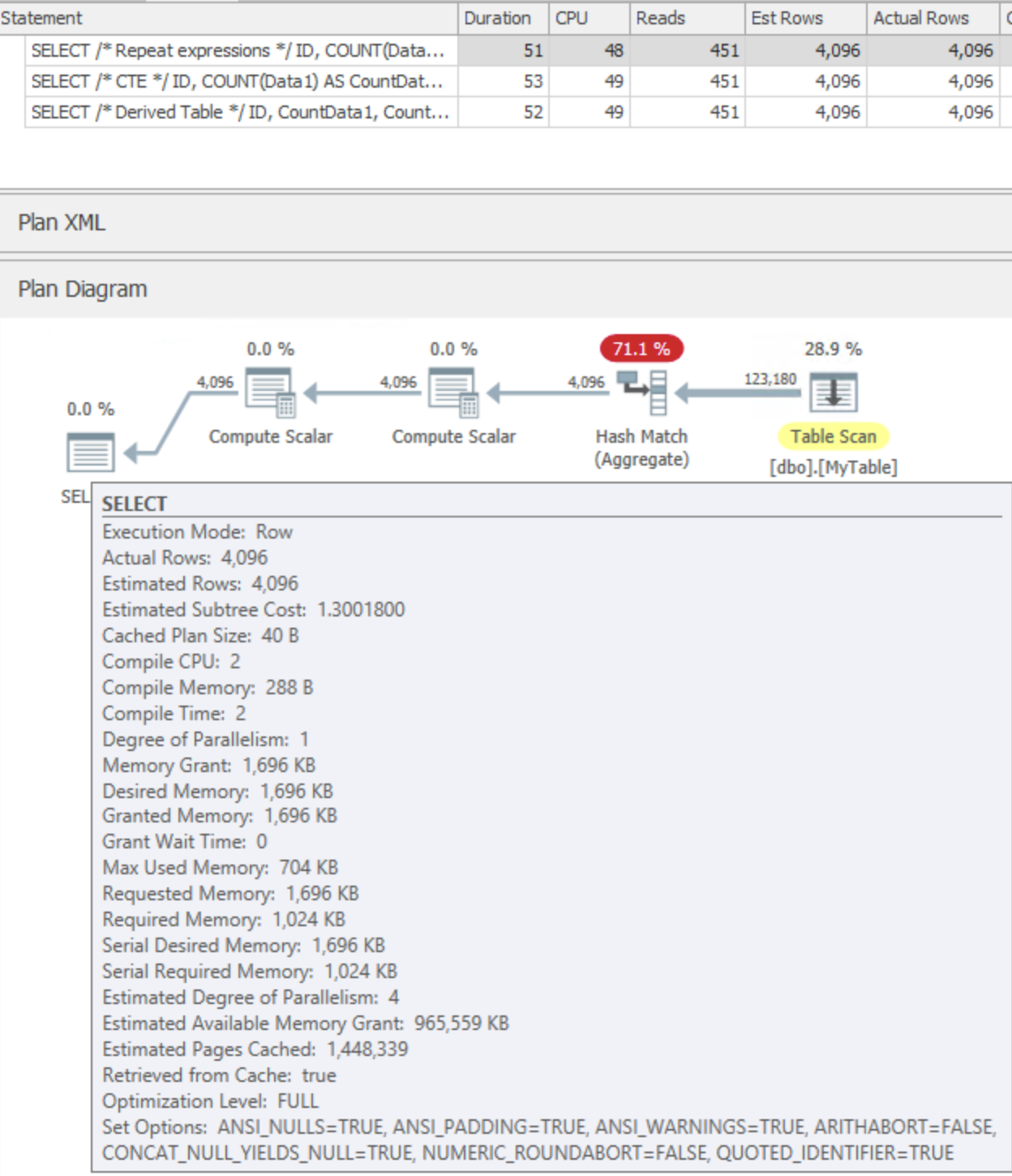
If you have a case where the CTE yields a better plan than repeating the expressions (noting that there are possibly some cases where both variations will yield multiple count expressions), please post it somewhere.
CodePudding user response:
SELECT TT.ID,TT.CountData1,TT.CountData2,
CASE WHEN TT.CountData1>= 4 and TT.CountData2>=4 THEN 1 ELSE 2 END CODE
FROM
(SELECT ID,
COUNT(Data1) AS CountData1,
COUNT(Data2) AS CountData2
FROM
Table
GROUP BY
ID)TT;