I need help to change the structure to a pandas dataframe with many columns like the example:
original dataframe:
| xx | yy | zz | a | b | c | k |
|:---|:---|:---|:--|:--|:--|:--|
| x1 | y1 | z1 | 0 | 2 | 1 | 3 |
| x2 | y2 | z2 | 1 | 0 | 2 | 0 |
I need just the first 3 columns and change the rest
new dataframe:
| xx | yy | zz | valor | nueva columna|
|:---|:---|:---|:--|:--|
| x1 | y1 | z1 | 0 | a |
| x1 | y1 | z1 | 2 | b |
| x1 | y1 | z1 | 1 | c |
| x1 | y1 | z1 | 3 | k |
| x2 | y2 | z2 | 1 | a |
| x2 | y2 | z2 | 0 | b |
| x2 | y2 | z2 | 2 | c |
| x2 | y2 | z2 | 0 | k |
I get a solution with a for loop, but in colab when the columns and rows are many the time is excessive
CodePudding user response:
df1 = df.set_index(['xx','yy','zz']).stack()
df1.reset_index()
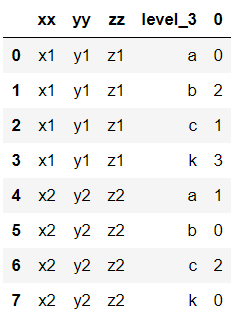
CodePudding user response:
As suggested by @HenryYik, melt works and provide the expected result :
>>> pd.melt(df, id_vars=['xx', 'yy', 'zz'], value_vars=['a', 'b', 'c', 'k']).sort_values(by=['xx'])
xx yy zz variable value
0 x1 y1 z1 a 0
2 x1 y1 z1 b 2
4 x1 y1 z1 c 1
6 x1 y1 z1 k 3
1 x2 y2 z2 a 1
3 x2 y2 z2 b 0
5 x2 y2 z2 c 2
7 x2 y2 z2 k 0
UPDATE :
As suggested by @Nesha25, a sort_values is added to get the exact expected output. Thanks @Nesha25.