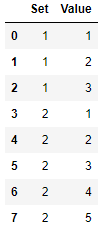
Creating the dataframe:
df = pd.DataFrame({'Set': [1, 1, 1, 2, 2, 2, 2, 2], 'Value': [1, 2, 3, 1, 2, 3, 4, 5]})
results in the DataFrame as shown below.
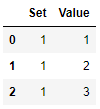
Next I perform a groupby operation by Set, and the first group is shown below.
grouped_by_Set = df.groupby('Set')
grouped_by_Set.get_group(1)
Now I want to select all but the last entry in the Value column per group. I can select the first three (for example) and last entry per group using grouped_by_Set.nth([0, 1, 2]) and grouped_by_Set.nth(-1), however selecting all but the last entry per group does not work with grouped_by_Set.nth(0:-1). I cannot specify the entries explicitly as the groups have different lengths.
CodePudding user response:
IIUC, you can do with iloc in apply
print(df.groupby('Set').apply(lambda x: x.iloc[:-1]).reset_index(drop=True))
Set Value
0 1 1
1 1 2
2 2 1
3 2 2
4 2 3
5 2 4
or you could use duplicated and keep='last' to create a mask, then use this mask with loc
print(df.loc[df.duplicated(subset='Set', keep='last')])
Set Value
0 1 1
1 1 2
3 2 1
4 2 2
5 2 3
6 2 4
CodePudding user response:
You could use tail(1) to get the last entry of every group and then use the index to deselect it from the original dataframe by inversing isin:
df[~df.index.isin(df.groupby("Set").tail(1).index)]
# Output:
Set Value
0 1 1
1 1 2
3 2 1
4 2 2
5 2 3
6 2 4
CodePudding user response:
Try this using reset_index(drop=True) .max() methods, the idea is to use the index for each group in order to set the start and the end of the slice operation:
grouped_by_Set = df.groupby('Set')
group = grouped_by_Set.get_group(1).reset_index(drop=True)
start = group.index[0]
end = group.index.max()
df_output = group.iloc[start:end, :]
print(df_output)
Output:
Group 1:
| Set | Value | |
|---|---|---|
| 0 | 1 | 1 |
| 1 | 1 | 2 |
Group 2:
| Set | Value | |
|---|---|---|
| 0 | 2 | 1 |
| 1 | 2 | 2 |
| 2 | 2 | 3 |
| 3 | 2 | 4 |