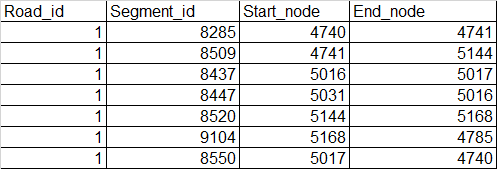
I have a few thousand of roads that each are made up of one to several segments. For each segment, there is a start and end node. How do I sort them so that I can get the start and end node of the road? A sample of one road data is as shown.
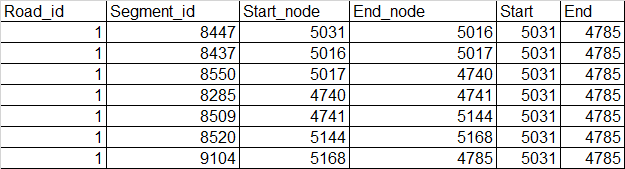
After I know the start node and end node of the road, I want to apply this information to each segment of the road to create the following table.
import pandas as pd
data = [['Road_id','Segment_id','Start_node','End_node'], [1,8285,4740,4741], [1,8509,4741,5144], [1,8437, 5016,5017], [1,8447, 5031, 5016], [1, 8520, 5144,5168], [1,9104,5168,4785],[1,8550,5017,4740]]
df = pd.DataFrame(data[1:], columns = data[0])
CodePudding user response:
Perhaps this will give you a start. This does the topological sort and prints out the segments in order. You'll have to extend this to deal with multiple roads.
data = [
['Road_id','Segment_id','Start_node','End_node'],
[1,8285,4740,4741],
[1,8509,4741,5144],
[1,8437,5016,5017],
[1,8447,5031,5016],
[1,8520,5144,5168],
[1,9104,5168,4785],
[1,8550,5017,4740]
]
# Reorganize the data a bit.
rows = {}
nexts = {}
starts = set()
ends = set()
for row in data:
if isinstance(row[0],str):
title = row
continue
rows[row[2]] = row
nexts[row[2]]=row[3]
starts.add(row[2])
ends.add(row[3])
# Find the start without an end, and the end without a start.
start = (starts-ends).pop()
end = (ends-starts).pop()
# Go print out the rows along this route.
node = start
while node in nexts:
print(rows[node])
node = nexts[node]
Output:
(1, 8447, 5031, 5016)
(1, 8437, 5016, 5017)
(1, 8550, 5017, 4740)
(1, 8285, 4740, 4741)
(1, 8509, 4741, 5144)
(1, 8520, 5144, 5168)
(1, 9104, 5168, 4785)