I have a pandas dataframe with 3 columns (CHAR, VALUE, and WEIGHT).
CHAR column contains duplicate values which I need to group ['A', 'A', 'A', 'B', 'B', 'C'].
VALUE column has a unique value for every unique CHAR [10, 10, 10, 15, 15, 20].
WEIGHT column has various values [1, 2, 1, 4, 4, 6].
Consider an example of my initial dataframe:
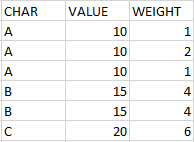
I need to create a new dataframe which will have 3 columns.
- CHAR which will not have any duplicates
- T_VALUE (total value) which will have a sum of this CHAR's value and all its weights
- T_WEIGHT (total weight) which will have a sum of this CHAR's weights
Result would look like this:
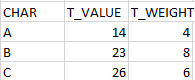
I would highly appreciate any help.
CodePudding user response:
You could use = instead:
newDF = df.groupby(['CHAR', 'VALUE'], as_index=False)['WEIGHT'].sum()
newDF['VALUE'] = newDF['WEIGHT']
CodePudding user response:
I was actually able to answer my own question. Here is the solution:
d = {'CHAR': ['A', 'A', 'A', 'B', 'B', 'C'],
'VALUE': [10, 10, 10, 15, 15, 20],
'WEIGHT': [1, 2, 1, 4, 4, 6]}
df = pandas.DataFrame(data=d)
newDF = df.groupby(['CHAR', 'VALUE'], as_index=False)['WEIGHT'].sum()
newDF['VALUE'] = newDF['VALUE'] newDF['WEIGHT']