I have a df that looks like this:
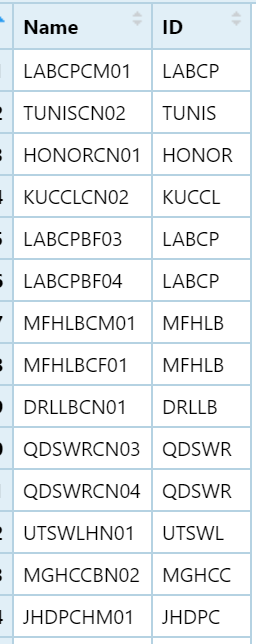
I want to remove the part that is equal to ID from Name, and then build three new variable which equal to the last two digit of Name, the 3 place in Name', and 4th place in Name". sth that will look like the following:
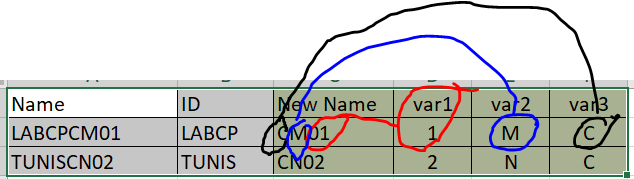
What should I do in order to achieve this goal?
df<-structure(list(Name = c("LABCPCM01", "TUNISCN02", "HONORCN01",
"KUCCLCN02", "LABCPBF03", "LABCPBF04", "MFHLBCM01", "MFHLBCF01",
"DRLLBCN01", "QDSWRCN03", "QDSWRCN04", "UTSWLHN01", "MGHCCBN02",
"JHDPCHM01", "UNILBCF03", "UTSWLGN03", "PHCI0CN01", "PHCI0CN02"
), ID = c("LABCP", "TUNIS", "HONOR", "KUCCL", "LABCP", "LABCP",
"MFHLB", "MFHLB", "DRLLB", "QDSWR", "QDSWR", "UTSWL", "MGHCC",
"JHDPC", "UNILB", "UTSWL", "PHCI0", "PHCI0")), row.names = c(NA,
-18L), class = c("tbl_df", "tbl", "data.frame"))
CodePudding user response:
We can use str_remove and then create the 'var' columns with substr
library(dplyr)
library(stringr)
df %>%
mutate(New_Name = str_remove(Name, ID),
var1 = readr::parse_number(New_Name),
var2 = substr(New_Name, 2, 2),
var3 = substr(New_Name, 1, 1))
-output
# A tibble: 18 × 6
Name ID New_Name var1 var2 var3
<chr> <chr> <chr> <dbl> <chr> <chr>
1 LABCPCM01 LABCP CM01 1 M C
2 TUNISCN02 TUNIS CN02 2 N C
3 HONORCN01 HONOR CN01 1 N C
4 KUCCLCN02 KUCCL CN02 2 N C
5 LABCPBF03 LABCP BF03 3 F B
6 LABCPBF04 LABCP BF04 4 F B
7 MFHLBCM01 MFHLB CM01 1 M C
8 MFHLBCF01 MFHLB CF01 1 F C
9 DRLLBCN01 DRLLB CN01 1 N C
10 QDSWRCN03 QDSWR CN03 3 N C
11 QDSWRCN04 QDSWR CN04 4 N C
12 UTSWLHN01 UTSWL HN01 1 N H
13 MGHCCBN02 MGHCC BN02 2 N B
14 JHDPCHM01 JHDPC HM01 1 M H
15 UNILBCF03 UNILB CF03 3 F C
16 UTSWLGN03 UTSWL GN03 3 N G
17 PHCI0CN01 PHCI0 CN01 1 N C
18 PHCI0CN02 PHCI0 CN02 2 N C
CodePudding user response:
You can use a combination of lapply and str_split to get the parts that do not contain the same values in ID, and then you can use substring from there.
df %>%
mutate(new_name = unlist(lapply(str_split(Name, ID), function(f) f[[2]]))) %>%
mutate(var1 = substring(new_name, 4, 4),
var2 = substring(new_name, 2, 2),
var3 = substring(new_name, 1, 1))
CodePudding user response:
How about:
R> df <- data.frame(f1=as.factor(c("LABCPCM01","TUNISCN02", "HONORCN01", "KUCCLCN02")))
R> tidyr::separate(df, f1, sep=c(5,6,7), into=c("ID", "var3", "var2", "var1"))
ID var3 var2 var1
1 LABCP C M 01
2 TUNIS C N 02
3 HONOR C N 01
4 KUCCL C N 02