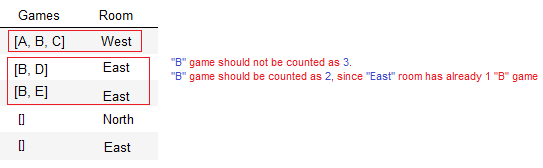
- A, B, C, D, E are games. There are 80 different games
- This dataframe has 5,000 rows
How can I list top 3 games, in terms of amount?
CodePudding user response:
First use DataFrame.explode for lists to scalars, then remove duplicates by DataFrame.drop_duplicates and last get top3 by Series.value_counts with Series.head, because value_counts sorting by default:
top3 = df.explode('Games').drop_duplicates(['Games','Room'])['Games'].value_counts().head(3)
CodePudding user response:
Explode your Games columns (if Games contains real Python list) then drop duplicates (according your side notes) and use value_counts with different parameters according to what you want:
- Top 3 for all rooms:
>>> df.explode('Games') \
.drop_duplicates(['Games', 'Rooms']) \
.value_counts('Games').head(3)
Games
A 2
B 2
C 2
dtype: int64
- Top 3 per room:
>>> df.explode('Games') \
.drop_duplicates(['Games', 'Rooms']) \
.value_counts(['Games', 'Rooms']).head(3)
Games Rooms
A North 1
West 1
B East 1
dtype: int64
Setup:
data = {'Games': [['A', 'B', 'C'], ['B', 'D'], ['B', 'E'], ['A', 'C'], ['D']],
'Rooms': ['West', 'East', 'East', 'North', 'South']}
df = pd.DataFrame(data)
print(df)
# Output:
Games Rooms
0 [A, B, C] West
1 [B, D] East
2 [B, E] East
3 [A, C] North
4 [D] South