I have a csv file and a python script in which I use pandas and matplotlib to plot the values. The script is
#!/usr/bin/env python3
import matplotlib.pyplot as plt
import numpy as np
import pandas as pd
import sys
def main(argv):
in_csv_file=argv[0]
print(argv[0])
df= pd.read_csv(in_csv_file)
print(df.head())
print(df.columns.tolist())
df.plot(kind='line',x='Frame',y='Confidence',color='blue', grid=True)
#plt.show()
plt.savefig('output.png')
if __name__ == '__main__':
main(sys.argv[1:])
This works without problems when all lines in the csv has a unique value for "Frame". But what happens if I have for example this csv
Frame,V1,V2,V3,V4,V5,Confidence
1,0,0,0,0,0,0
2,0,0,0,0,0,0
3,0,0,0,0,0,0
4,0,0,0,0,0,0
5,0,0,0,0,0,0
6,4,2,3,3,4,0.5
7,4,2,3,3,4,0.7
8,4,2,3,3,4,0.7
9,4,2,3,3,4,0.9
9,4,2,3,3,4,0.5
10,4,2,3,3,4,0.7
11,4,2,3,3,4,0.9
12,4,2,3,3,4,0.6
13,4,2,3,3,4,0.5
14,4,2,3,3,4,0.3
15,0,0,0,0,0,0
In this case I got a plot like
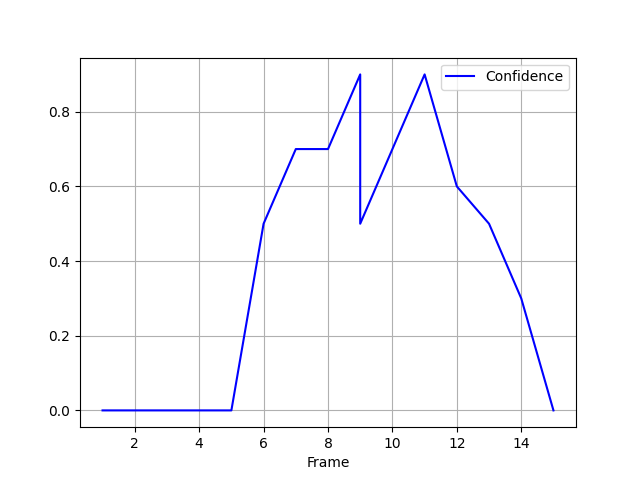
However I would like a plot more like
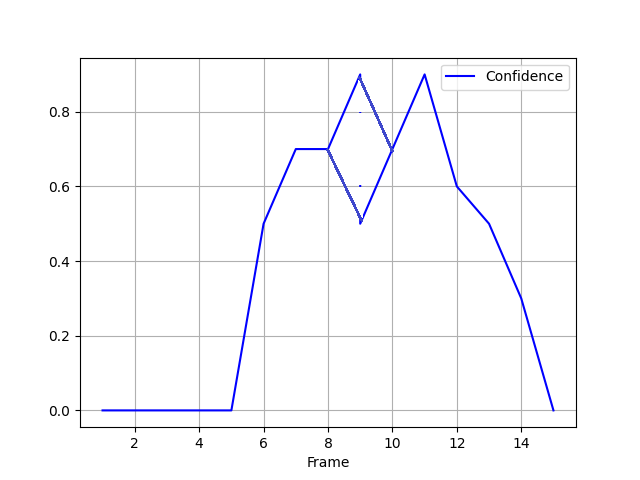
As you can see the values from 8 is followed by two values for 9 and then one for 10.
Is this possible, and how can I modify the code to handle it?
CodePudding user response:
One way is to pivot you data and plot:
(df.assign(count=df.groupby('Frame').cumcount())
.pivot(index='Frame', columns='count', values='Confidence')
.ffill(axis=1)
.plot(color='C0', legend=None, ylabel='Confidence')
)
Which gives:
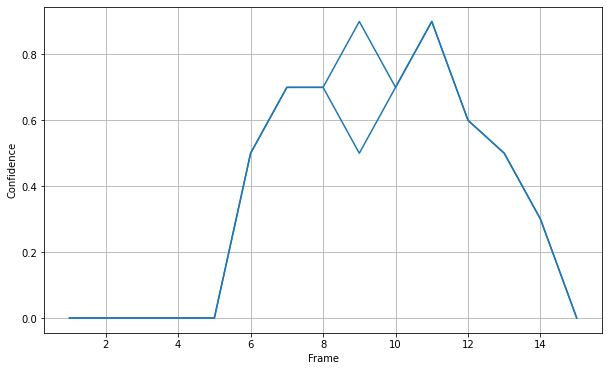
Now, this may give different output when there are two consecutive duplicates, e.g., what do you expect when there are two 8 frames?