Here is a sample of whats in the .csv file: Entity,Code,Year,Life expectancy (years) Afghanistan,AFG,1950,27.638 Afghanistan,AFG,1951,27.878 Afghanistan,AFG,1952,28.361 Afghanistan,AFG,1953,28.852 Afghanistan,AFG,1954,29.35 Afghanistan,AFG,1955,29.854 Afghanistan,AFG,1956,30.365 Afghanistan,AFG,1957,30.882 Afghanistan,AFG,1958,31.403 Afghanistan,AFG,1959,31.925 Afghanistan,AFG,1960,32.446 Afghanistan,AFG,1961,32.962 Afghanistan,AFG,1962,33.471 Afghanistan,AFG,1963,33.971 Afghanistan,AFG,1964,34.463 Afghanistan,AFG,1965,34.948 Afghanistan,AFG,1966,35.43 Afghanistan,AFG,1967,35.914 Afghanistan,AFG,1968,36.403 Afghanistan,AFG,1969,36.9 Afghanistan,AFG,1970,37.409 Afghanistan,AFG,1971,37.93 Afghanistan,AFG,1972,38.461 Afghanistan,AFG,1973,39.003 Afghanistan,AFG,1974,39.558 Afghanistan,AFG,1975,40.128 Afghanistan,AFG,1976,40.715 Afghanistan,AFG,1977,41.32
CodePudding user response:
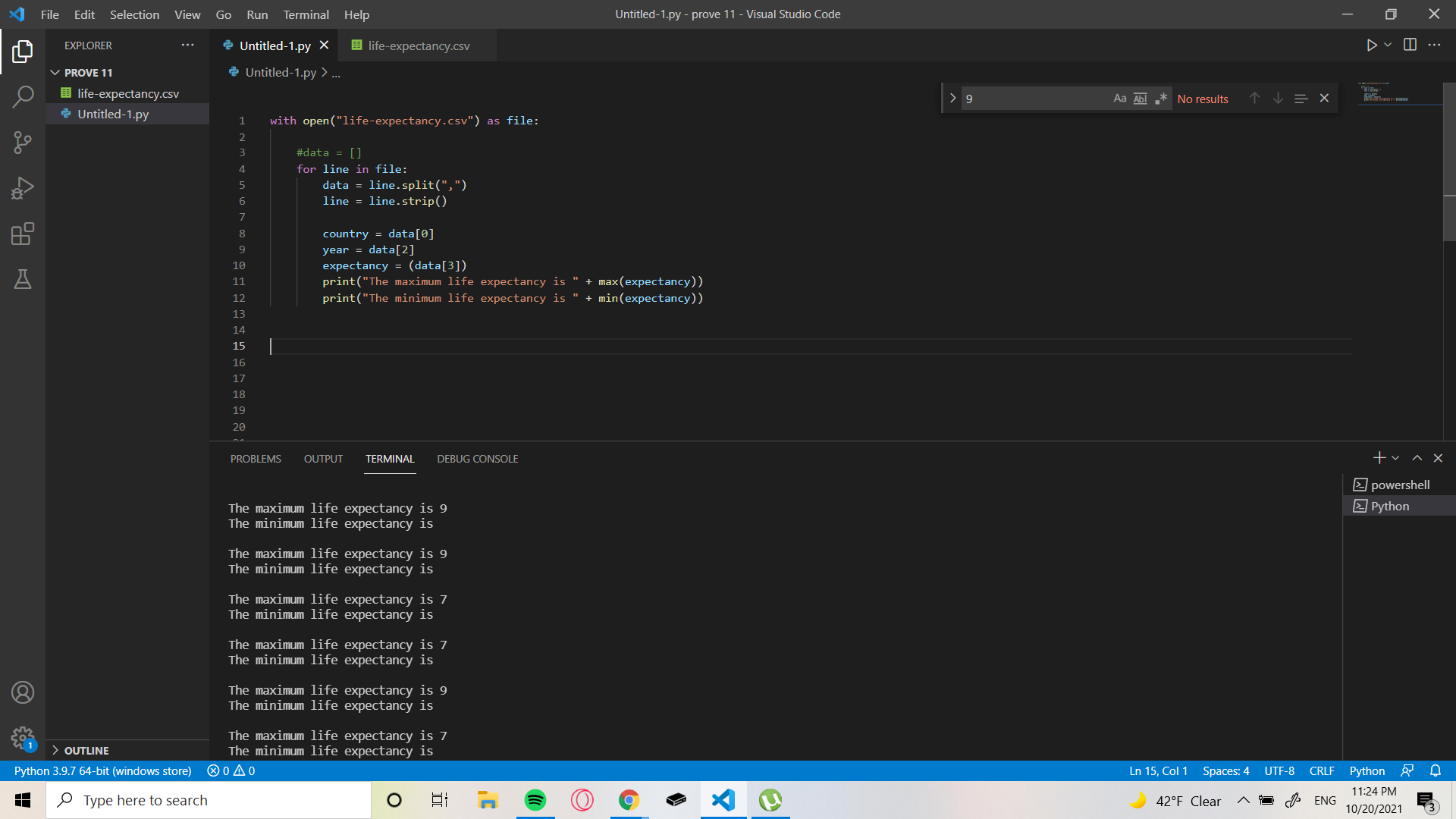
you are running a for loop and then just storing each line in the form of a list in the data variable. So, max(expectancy) does nothing in your case. The way max works in python is max(a,b) returns the maximum value among a and b.
Anyways, for your problem. Store the excel file into a dataframe.
import pandas as pd
df = pd.read_csv ('file_name.csv')
now df contains the data frame with your csv content.
To find the maximum, what you can do is:
df.nlargest(1, 'Life expectancy')
//here 'Life expectancy' is the column name in your csv.
similarly for the smallest,
df.nsmallest(1, 'Life expectancy')
//here 'Life expectancy' is the column name in your csv
CodePudding user response:
You sample data probably doesn't look the way it's presented in the question. I expect (and assume) that each line has just 4 tokens.
The answer presented here may look over-complicated but what it does is allow for your CSV file to contain data (in the same assumed format) for multiple different countries and is generally robust.
D = dict()
with open('life_expectancy.csv') as csv:
for line in csv:
try:
tokens = line.split(',')
assert len(tokens) == 4
v = float(tokens[3])
D.setdefault(tokens[0], []).append(v)
except (AssertionError, ValueError):
pass
for k, v in D.items():
print(f'Maximum life expectancy for {k} is {max(v):.2f}')
print(f'Minimum life expectancy for {k} is {min(v):.2f}')