I am trying to get specific table (by id) from downloaded html and parse it I´ve tried few ways and my last code is
var url = @"C:\Users\name\Plocha\web.html";
var doc = new HtmlDocument();
doc.Load(url);
string data = "";
int i = 2;
foreach (HtmlNode table in doc.DocumentNode.SelectNodes("//table"))
{
Console.WriteLine($"Found: {table.Id}");
if (table.Id == "formTbl")
{
foreach (HtmlNode row in table.SelectNodes("//tr"))
{
foreach (HtmlNode cell in row.SelectNodes("td"))
{
if (i == 1)
{
data = $"Column:{cell.InnerText}";
i = 2;
}
else if (i == 2)
{
data = $"Row: {cell.InnerText}";
Console.WriteLine(data);
data = "";
i = 1;
}
}
}
}
else
{
Console.WriteLine("Not what we want");
}
}
The problem is that it print all tables from webpage even tho I have specified to continue only if id = formTbl.
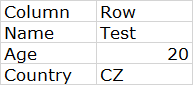
How data looks on table (theres no Name of columns its just two rows, in first row is name of column and in second row is value)
CodePudding user response:
SelectNodes() takes an XPath query. Some useful examples here. A particular one that is relevant to your case is this: //book - Selects all book elements no matter where they are in the document.
This means that instead of using "//tr" (searches the whole doc), you should look for "tr" if you want to respect the scope.
You could even use xpath to do the id searching AND selecting the <tr> underneath, using a single query:
foreach (var row in doc.DocumentNode.SelectNodes("//table[@id='formTbl']/tr"))
{
// ...do <tr> stuff
foreach (var cell in row.SelectNodes("td"))
{
// ... do <td> stuff
}
}
CodePudding user response:
foreach (var table in doc.DocumentNode.SelectNodes("//table[@id='formTbl']"))
{
foreach (var row in table.SelectNodes("tbody/tr"))
{
Console.WriteLine(row.Id);
foreach (var cell in row.SelectNodes("td"))
{
Console.WriteLine(cell.InnerText);
}
}
}
Problem was that I hasn't used tbody/tr
Thanks to @NPras