I do have the following alias, to show me the commit history of any given file:
file-history = log --follow --date-order --date=short -C
It works well, but never shows "merge commits", while the file can have been modified in a branch we did merge into main, for example.
The solution is to add the option -m, but then it shows many, many, many merge commits, for which most of them seem unrelated to the commit history of the file.
What is the right way to write such an alias to make it behave correctly (like in BitBucket, for this matter): showing all commits that did change a file, and only those?
EXTRA INFORMATION --
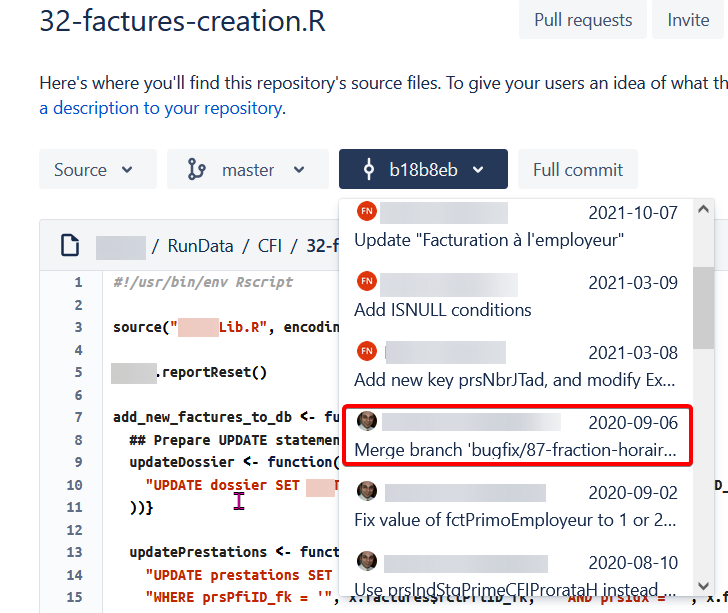
Using -m shows way too many commits; concretely:
(In red rectangles, what I should see... that's what BitBucket displays...)
(BTW, I don't understand why the commit da3c94a1 is duplicated.)
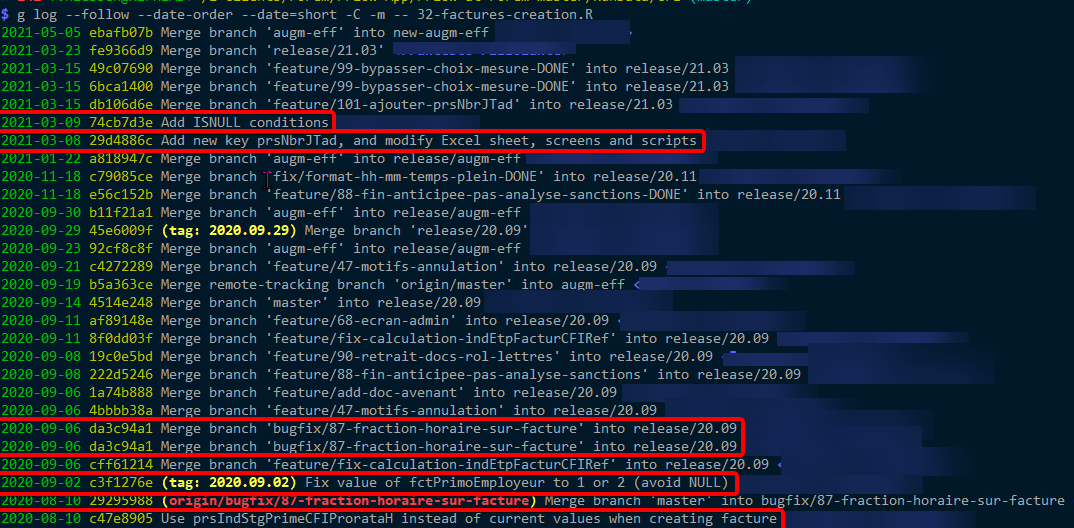
Using -c shows even much more commits (the first commit that should be reported being in the bottom of the page) and displays the diffs (what I don't want to see here):
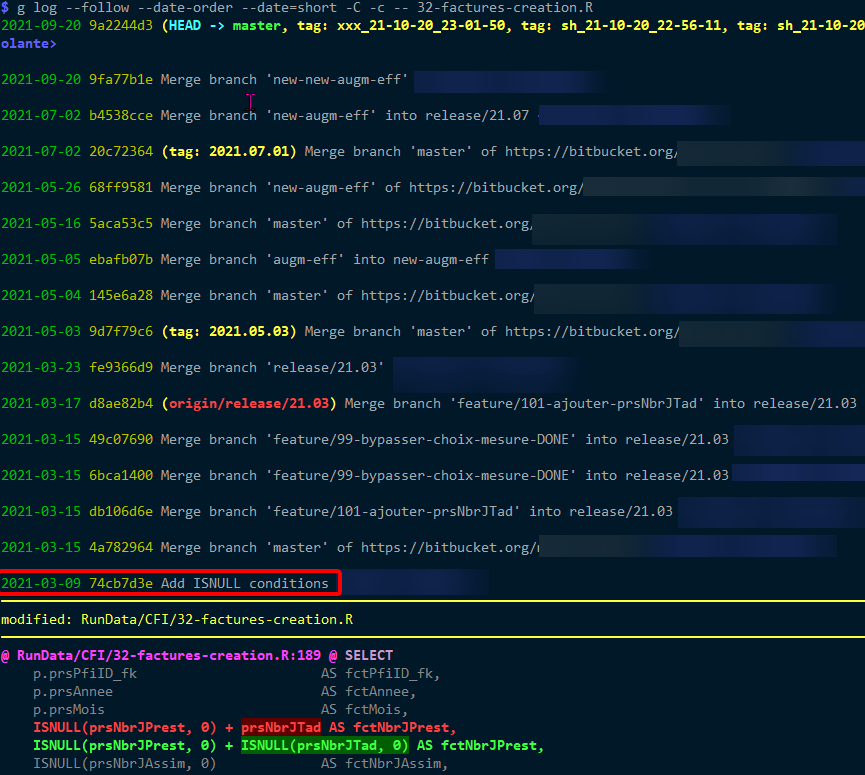
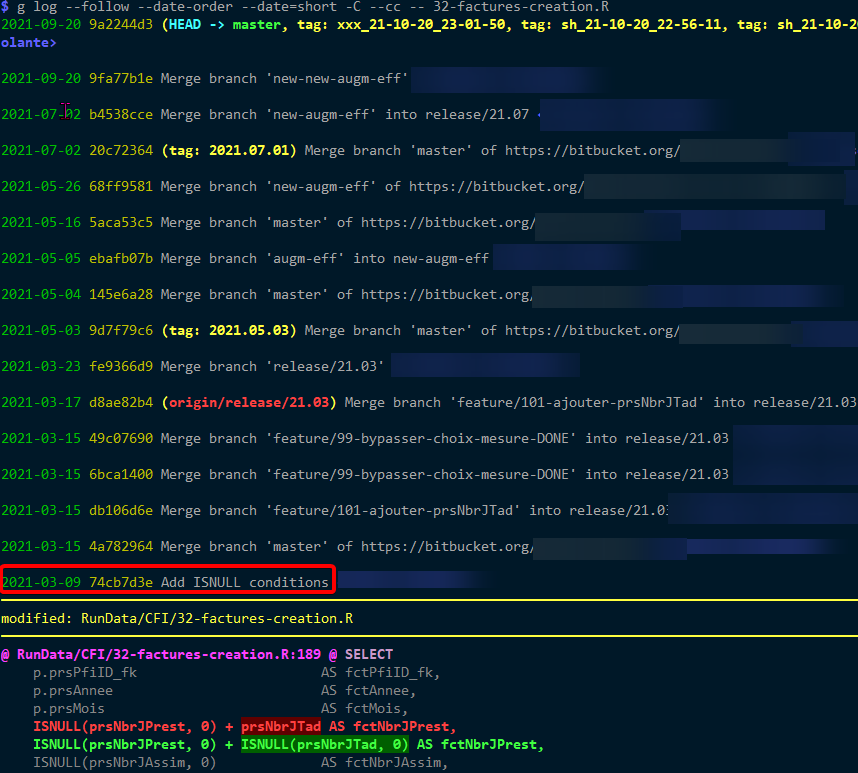
Same results for --cc:
And --first-parent shows weird results (as I don't see at all the commits I'm interested in):
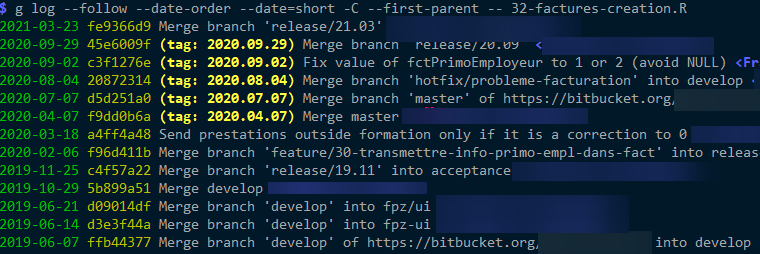
NEW EXTRA INFORMATION --
And, with --first-parent -m, no change:
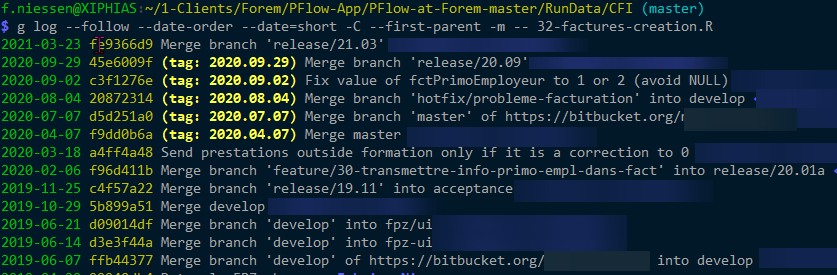
CodePudding user response:
but never shows "merge commits", while the file can have been modified in a branch we did merge into main, for example
If you're going to do this, add --first-parent -m (as I see @torek suggests in the comments). Not just -m, which by itself is more of a forensic tool for desperation cases only.
What's going on here is, without --first-parent Git's already going to show you those changes, in the commit(s) that made them. The merge isn't introducing any new changes. If Git showed you the merge diffs, it'd wind up showing you everything at least twice.
This is why it's such a good idea to avoid introducing new work or corrections in a merge commit. The act makes it impossible to reason about what the merge does. Merge conflict detection and resolution is already unbounded. Git does as well as any vcs can, and better than I think every other vcs on the planet, but it can't ever be perfect. Say a value in a list has to have some mathematical relation to a sum of the remaining values, the changes on both branches preserved that relation but when combined, that relation is broken. Or any other such condition: code is added in one branch that depends on an existing compiled-in value, but the other branch makes it user-configurable. Think about that one for a while.
So --first-parent -m -p will show you the diffs even for merges, but only changes introduced by the merged branch and conflict resolutions, work done earlier in the mainline will show up in the commits that introduced it.
CodePudding user response:
*You asked specifically about looking for merge commits in your output. I think now, based on all the comments under the question, this was a mistake: you don't want the merge commits at all, even if they do change the file in question. What you want is to stop git log from performing History Simplification.
To do that, simply provide the --full-history flag to git log. But it's also important to know what this flag means: in particular, I don't think you understand what Git is trying to show you here (which is not surprising, as Git documentation does a terrible job of explaining what Git is trying to do in the first place).
To get to the aha! moment, we have to start with a simple review of stuff probably already know but may have shoved into the back of your mind and forgotten about:
- Git is all about commits, and each commit is a numbered entity, found by its big ugly random-looking hash ID;
- each commit stores a snapshot and some metadata, and the metadata include the raw hash ID of some set of earlier commits; and
- most commits store just one previous commit hash ID.
This makes commits form simple backwards-looking chains. Let's use simple uppercase letters as pretend hash IDs, and allocate them sequentially to make things easy for our puny human brains, and imagine we have a repository that ends with a commit with hash ID H, like this:
A <-B <-C ... <-F <-G <-H
That is, the last—and therefore latest—commit in this repository is commit H. Commit H stores both a full snapshot of every file and a backwards-pointing arrow (really, the true commit hash ID of) earlier commit G.
Using the stored snapshot in G and the stored snapshot in H, Git can compare the two snapshots. Whatever is different here, those are the files we changed; by comparing those files, Git can produce a diff, showing the particular lines we changed, or Git can just make a list of the files that we changed. That's pretty straightforward, but it does mean that to know what changed in H, Git must extract both snapshots: the one from H, but also the one from its parent G.
The git log command will do this for H, then move back one step to G. Now, to see what changed in G, Git must compare the snapshot of its parent F to the snapshot in G. That suffices for knowing what changed in G.
Now git log can step backwards yet again. This repeats as needed, until we have run all the way back to the very first commit, which—by definition—simply adds all the files it has in its snapshot. There's nothing before the root commit A, so everything is new, and now git log can stop.
Merges mess with this
That works fine for these simple linear chains, but Git's commits are not always simple linear chains. Suppose we have our simple-so-far repository, where there is only one branch named main and it ends at H, but now we make some new branch names, make some commits on these new branches, and get ready to merge them:
I--J <-- br1
/
...--G--H
\
K--L <-- br2
Commits up through H are on all branches, while commits I-J are only on br1 and commits K-L are only on br2. Using git log at this point shows us J, then I, then H, then G, etc., following the arrows backwards from br1's latest commit; or, it shows us L, then K, then H, then G, etc., following the arrows backwards from br2's latest commit.
Git will of course find file "changes" in the usual way: compare the snapshot in L vs that in K, or K vs H, etc. Since every commit has exactly one parent commit, this works fine.
Once we merge, however, we have a problem. The merge itself works by:
- comparing
HvsJto see what changed onbr1; - comparing
HvsLto see what changed onbr2; and - combining these changes, and applying the combined changes to the snapshot in
H.
This keeps "our" changes on br1 and adds "their" changes on br2, if that's the direction we're doing the merge. Or, it keeps "our" changes on br2 and adds "their" changes on br1. Either way the result is the same (except for conflict resolutions, if any, which depend on how we choose to resolve the conflict).
We now have Git make a new merge commit, M, which has:
- one snapshot, but
- two parents.
It looks like this:
I--J
/ \
...--G--H M
\ /
K--L
I have taken the labels away because at this point we often do that: M is now the latest main commit instead, and when we add another new commit N it just extends main:
I--J
/ \
...--G--H M--N
\ /
K--L
N is an ordinary single parent commit as usual, so the niceness of comparing the snapshot in M vs that in N works as usual, finding the changes as usual.
Merge commit M, on the other hand, is quite thorny. How should git log show the changes? Changes, in Git, require that we look at "the" parent commit. But M does not have the parent. M has two parents, J and L. Which one should we use?
The -m flag means run two separate git diff operations, one against J, and then a second one against L. That way we'll see what changed vs J, i.e., what we brought in via K-L, and then we'll also see what changed vs L, i.e., what we brought in via I-J.
Adding --first-parent means follow just one of these lines so that at M we'll see, e.g., what happened in K-L, but then we won't look at K or L at all any more. We'll just move back to J. The effect is that Git pretends, for the duration of -m --first-parent, that the commit graph looks like this:
...--G--H--I--J--M--N
This is, more or less, literally what you asked for—but it's not what Bitbucket is doing.
Undoing the merge mess several other ways
We can, if we so choose, have git log compare M vs both J and L—i.e., make two separate git diffs—but then discard most of the results of these two diffs. Git has two different "combined diff" modes, which you can get with -c or --cc.
Unfortunately, neither one does what you want. They're also rather difficult to explain (and I still don't really know what the true difference between the two is, though they are demonstrably different: I can show some differences, but I don't know what the goals are, of the two different options).
History Simplification
The real key here though is this. Suppose there is some file F that appears in all three commits M, J, and L. Remember, this particular snippet of our picture looks like this:
I--J
/ \
...--H M
\ /
K--L
- If F is the same in all three commits, it's not "interesting" in this merge. Nobody made any changes to it.
- If F matches in
JvsM, but is different inLvsM, then "something interesting" happened. The same is true if F matches inLvsM, but is different inJvsM.
What git log does in most cases here is to try to find out about the final state of the file. Why does file F look the way it does in M? But think about this: If F differs in J vs M but matches in L vs M, then anything we did to the file along the top row is irrelevant! We threw away the top-row copy of file F and kept only the bottom-row copy.
So, if you're asking git log about file F at this point, git log simply does not bother to look at commits I-J. It follows only the bottom row.
On the other hand, if F exactly matches in J-vs-M but differs in L-vs-M, git log -- F will follow only the top row, because we threw away anything that came out of the bottom row.
This is History Simplification in a nutshell. The git log command will, at merge points, throw out one "side" of the merge entirely if it can. If the file(s) we care about match one side, that's the side git log will pick. If the file(s) we care about match all sides of the merge, git log will pick one side at random, and follow that side.
This means git log never even looks at any of the files on the "other side" of the merge so you will not see any of those commits in the git log output. The program is assuming that since the merge took "one side" over the other, that's the interesting side, and everything that might show up on the other is irrelevant dross, to be discarded.
This is sometimes what you want
The reason git log does this kind of history simplification is that it assumes your goal is to know why the file looks the way it does in the latest version. Any irrelevant-dross-commits that got throw out don't matter, so let's not even look at them.
When that's what you want, that's what you want! But sometimes you want to know: I'm sure I changed this myself, where was that? or something similar. Here, you must tell git log not to do history simplification at all. The flag for this is --full-history. There are other history simplification flags, so that you can control the simplification: it is useful after all. Read through the git log documentation History Simplification section to see them.
It's worth adding one more point here, having to do with so-called evil merges (see Evil merges in git?). We could have:
...--J
\
M
/
...--L
where the snapshot files in M are utterly unrelated to the files in either J or L. More commonly, we might have some file in M that has a change hidden away in it that does not come from the top or bottom rows at all, but rather was produced due to the fact that there were conflicts and/or the combined changes didn't work.
If the "hidden" change is due to conflicts, that's not so bad, but if someone stuck in an unrelated fix, we have an issue. In particular, git log by default does not display merge commits at all when using git log -- path. It assumes that anything interesting that will show up from the path argument will be found on either the top or bottom row, in a commit before the merge. But an "evil merge" might introduce an "interesting change" that isn't in either row, and this is when you must force git log to look at merge commits, using -m, or -c, or --cc.
What Bitbucket do with their software is of course up to them. We don't know if they are currently using --full-history --cc for instance. We don't know whether, in future, they might change the internal git log options. So there's no real point in trying to make your command-line git log output exactly match your Bitbucket view output, as the latter is not under your control in the first place. If you are going to use git log, then, concentrate instead on knowing what git log is doing and how to make that work to your advantage.