I have the following query which I'm using to review the SQL Server execution plan.
SELECT TOP 1000
fact.division,
case when fact.division='east' then 'XXX' else 'YYY' end div,
count(1)
FROM
division join fact on (division.division=fact.division)
where
fact.division!='east'
group by
fact.division
And the plan is as follows:
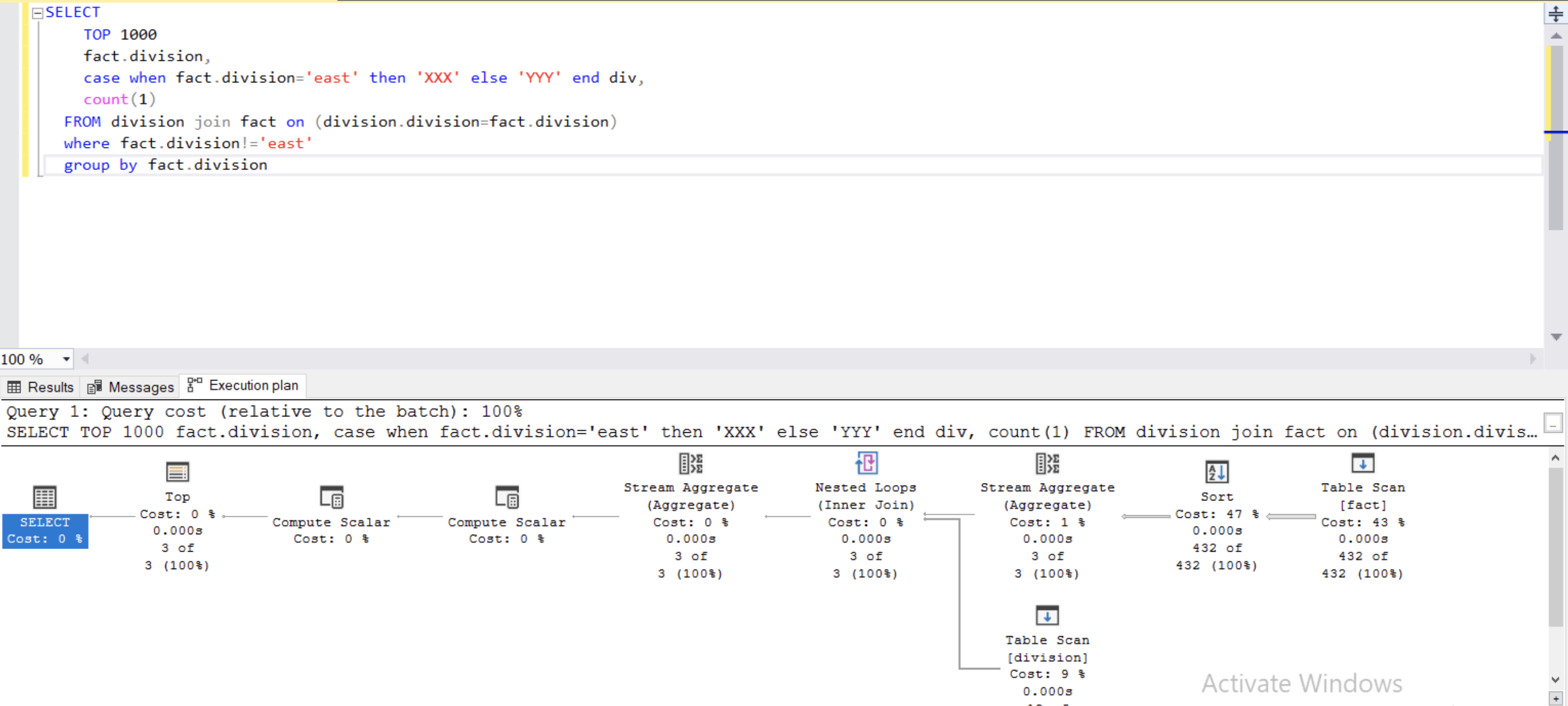
I have a few questions about the plan:
- Why does it do a Sort before the Aggregate?
- What are the two Stream Aggregate operations for? I could understand doing one after the join, but why two?
- Finally, what are the two "Compute Scalar" for? When I hovered over them I was expecting it to tell me something along the lines of "This is the
CASEstatement", but they were pretty opaque. How can I tell what the "Compute Scalar"s are doing?
CodePudding user response:
- Why does it do a Sort before the Aggregate?
A stream aggregate requires the input to be sorted by the group by columns. That way it receives all rows for one group together and can emit the aggregated total for the group (and reset the aggregations for the next group) when it sees that it has finished processing all rows for it.
- What are the two Stream Aggregate operations for? I could understand doing one after the join, but why two?
One optimisation that SQL Server can do is to do a partial aggregation before the join to reduce the number of rows going into the join and then calculate the final total after the join. If fact has three rows for division = 'west' it can collapse that down to 1 row and pass the value 3. It then just needs to do one lookup in the inner joined table rather than 3. It can then sum the join result to get the final total (i.e. if division has 2 matching rows. the SUM of 3 and 3 is 6)
In SSMS select the operator and look at the "properties" window (F4) to see the "Defined Values" for both stream aggregates.
The one to the right of the join has expression
[partialagg1008] = Scalar Operator(Count(*))
And the one after the join has
[globalagg1009] = Scalar Operator(SUM([partialagg1008]))
- Finally, what are the two "Compute Scalar" for? When I hovered over them I was expecting it to tell me something along the lines of "This is the
CASEstatement", but they were pretty opaque. How can I tell what the "Compute Scalar"s are doing?
You need to look at defined values for these too.
One of them has expression [Expr1006] = Scalar Operator(CONVERT_IMPLICIT(int,[globalagg1009],0)) and is casting the result of the COUNT aggregation back to int. Internally COUNT and COUNT_BIG use the same apparatus that returns bigint - for COUNT this needs a cast to get the final advertised datatype.
The other one is calculating the result of your CASE expression and has expression [Expr1007] = Scalar Operator(CASE WHEN [avails].[dbo].[fact].[Division]=N'east' THEN 'XXX' ELSE 'YYY' END)