If you have two Pandas dataframes in Python with identical axes, is there a function to merge the elements as tuples so that they maintain their positions? If there is a better way to combine these dataframes without duplicating the number of indices or columns, that works as well.
Expected logic:
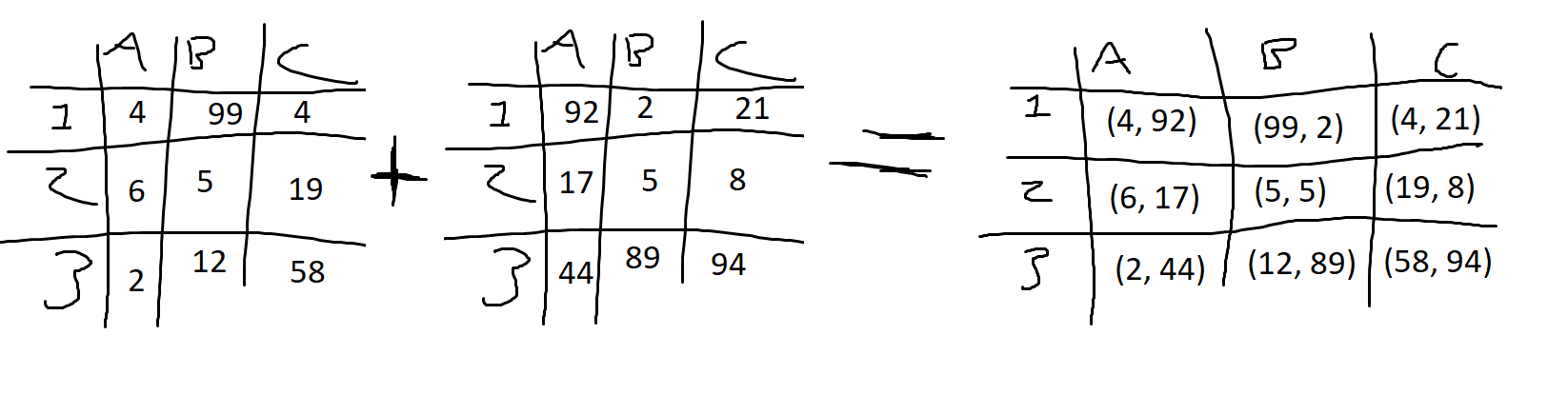
CodePudding user response:
You can do this in pure pandas:
(pd.concat([df1,df2])
.stack()
.groupby(level=[0,1])
.apply(tuple)
.unstack()
)
Output:
A B
0 (1, 7) (4, 10)
1 (2, 8) (5, 11)
2 (3, 9) (6, 12)
Input:
import pandas as pd
df1 = pd.DataFrame({"A":[1,2,3],"B":[4,5,6]})
df2 = pd.DataFrame({"A":[7,8,9],"B":[10,11,12]})
CodePudding user response:
The operation you're looking for seems like "zip". That is, match elements of two sequences together into a sequence of tuples. If you look at each column in your dataframes and zip them together you will have a result that is a list of lists of tuples - what you want to be in your result dataframe. You can then construct a dataframe with the same columns and index out of that data. In code, that looks like this:
data = [list(zip(df1[col], df2[col])) for col in df1]
pd.DataFrame(data, index=[1,2,3], columns=["A", "B", "C"])
CodePudding user response:
You can maybe use something like this to achieve what you want.
df3 = pd.DataFrame({x: zip(df1[x], df2[x]) for x in df1.columns})
CodePudding user response:
df1 = pd.DataFrame({"A" : [1,2,3], "B":[4,5,6]})
df2 = pd.DataFrame({"A" : [7,8,9], "B":[10,11,12]})
def add_dfs(df1, df2):
for col in df1.columns:
df1[col] = df1[col].apply(lambda x: (x,))
for col in df2.columns:
df2[col] = df2[col].apply(lambda x: (x,))
df = df1 df2 # using operator , satisfies answer technically
return df
df = add_dfs(df1, df2)