I was trying to find out the time window in which my dataframes values lie, but i am not able to understand the output. I am not able to understand how the: window(timeColumn, windowDuration, slideDuration=None, startTime=None) is working.
This is the code:
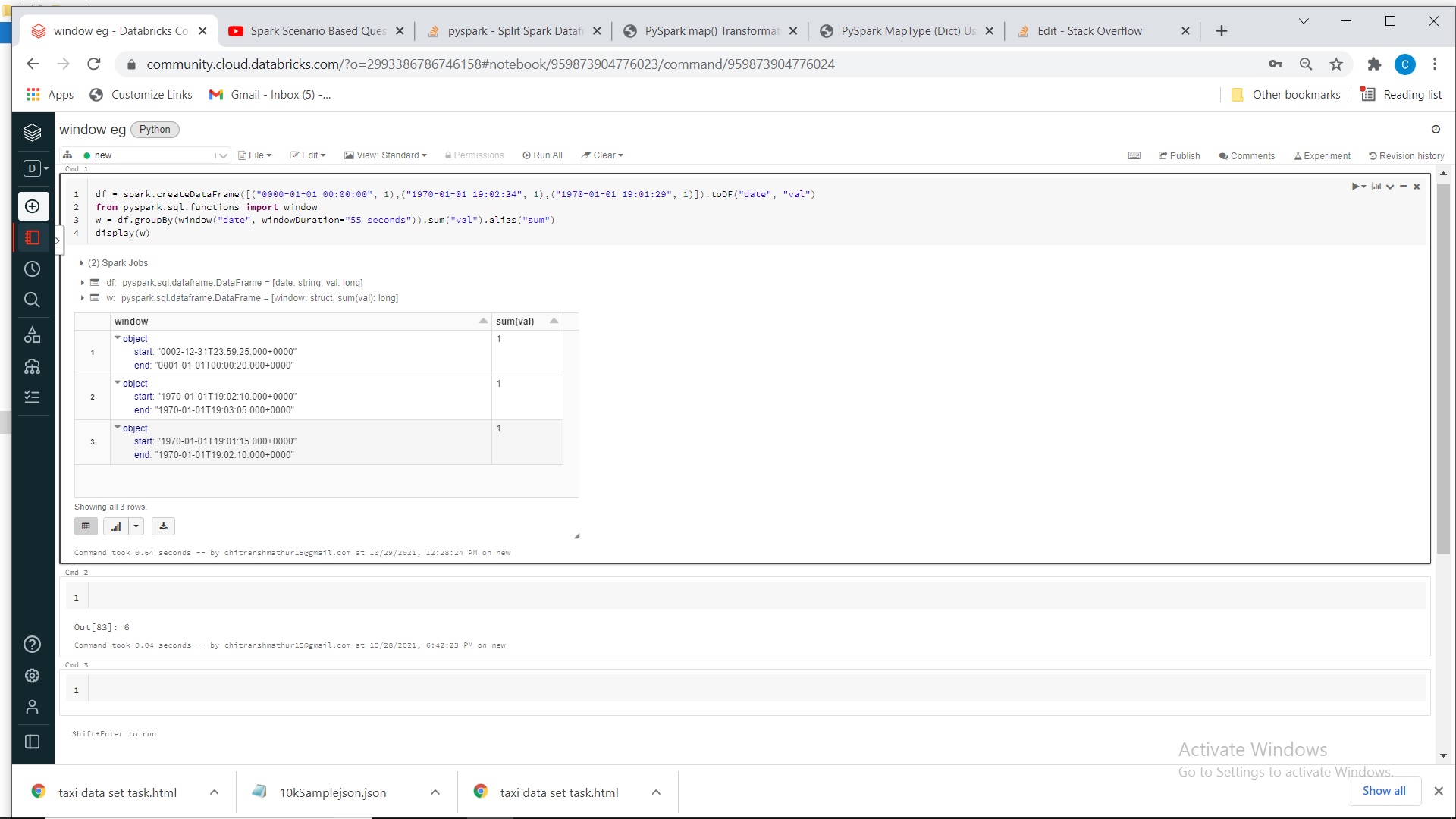
df = spark.createDataFrame([("0000-01-01 00:00:00", 1),("1970-01-01 19:02:34", 1),("1970-01-01 19:01:29", 1)]).toDF("date", "val")
from pyspark.sql.functions import window
w = df.groupBy(window("date", windowDuration="55 seconds")).sum("val").alias("sum")
display(w)
Using databricks.
Can someone please tell me the output and explain it how it works.
CodePudding user response:
From a timestamp column, window will create a "bucket" (start and end time) that contains the input timestamp. The "size" of the bucket depends on the windowDuration duration parameter.
For exemple, you have a timestamp 2021-10-29 11:13:51 and you apply the window function with windowDuration = "15 minutes", the new column will be a struct with start = "2021-10-29 11:00:00" and end = "2021-10-29 11:15:00". Between start and end, you have 15 minutes, and your timestamp is contained in between.
In your current code, you use windowDuration="55 seconds". According to the documentation:
The startTime is the offset with respect to 1970-01-01 00:00:00 UTC with which to start window intervals.
It means that from the date 1970-01-01 00:00:00, it will create windows of 55 secondes length. First one will be 1970-01-01 00:00:00 ==> 1970-01-01 00:00:55, seconde one will be 1970-01-01 00:00:55 ==> 1970-01-01 00:01:50, etc ...
It works but the start and end are not regular compare to a 1 minutes param for example.