I have a following dataframe:
import pandas as pd
data = [['1044', '1924'], ['1044', '1926'], ['1044', '1927'], ['1044', '1928'], ['1048', '1924'], ['1048', '1926'], ['1048', '1927'], ['1048', '1928'], ['1051', '1924'], ['1051', '1926'], ['1051', '1927'], ['1051', '1928'], ['1058', '']]
df = pd.DataFrame(data, columns = ['Col1', 'Col2'])
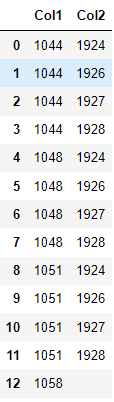
I would like to reduce the dataframe as shown here:
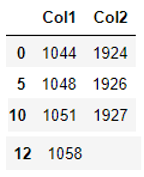
I have no clue how to do that, but it should be working as follows:
- keep the first duplicate in the column "Date" - in this example row 0
- drop the second duplicate in the column "Value" - in this example row 3
Hopefully it does exist a easier way how to perform it.
CodePudding user response:
You can build a new dataframe instead, with the unique values:
pd.DataFrame({key:pd.unique(value) for key, value in df.items()})
Out[252]:
Col1 Col2
0 1044 1924
1 1048 1926
2 1051 1927
CodePudding user response:
Here is another method that should work irrespective of the order, with an arbitrary number of columns, and which should be easy to customize if more complex selections are needed:
(df.assign(x=df.groupby('Col1').ngroup(),
y=df.groupby('Col1').cumcount())
.query('x==y') # this can be updated in case more complex selections are required
.drop(['x','y'], axis=1)
)
Output:
Col1 Col2
0 1044 1924
4 1048 1926
8 1051 1927
CodePudding user response:
I think, cumcount each column and check similarities between the outputs, Code below;
df =df.assign(Date_cumcount=df.groupby('Date').cumcount(),Value_cumcount = df.groupby('Value').cumcount())
out =df[df['Date_cumcount']==df['Value_cumcount']].drop(['Date_cumcount','Value_cumcount'],1)
Date Value
0 1044 1924
5 1048 1926
10 1051 1927
12 1058