I would like to combine all the rows the have a score column less than 63,
Then take some of all of them and save them in a new row we can call it 'new sum' it will be the sum of all scores that have a score less than or equal to 63.
drop that columns contain values less than 63.
I am using a panda.
Please see the attached picture
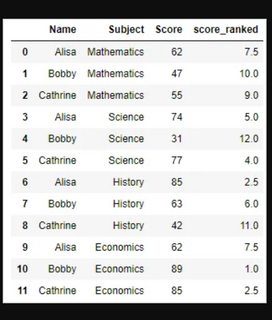
CodePudding user response:
Try df[df['Score'] > 63] df.groupby(['Name'])[Score].sum() i am writing it as answer because i can't comment
CodePudding user response:
You can use pandas built-in Fancy indexing:
df = df[df['score'] < 30]
df.loc[len(df.index)] = ["TOTAL","",sum(df['score']),""]
CodePudding user response:
You can do so as follows:
df.loc[len(df)] = ['Other', "", df[df['Score'] < 63]['Score'].sum(), ""]
If you want to remove the rows having Score < 63, you can do so as follows:
df.drop(df[df['Score'] < 63].index, inplace=True)
Note: The option, inplace=True changes the DataFrame permanently. If you do not want the change to be applied to the DataFrame permanently, omit this option e.g.
new_df = df.drop(df[df['Score'] < 63].index)
Demo:
import pandas as pd
import numpy as np
df = pd.DataFrame({
'Name': ['Alisa', 'Bobby', 'Cathrine', 'Alisa', 'Bobby', 'Cathrine', 'Alisa', 'Bobby', 'Cathrine', 'Alisa', 'Bobby',
'Cathrine'],
'Subject': ['Mathematics', 'Mathematics', 'Mathematics', 'Science', 'Science', 'Science', 'History', 'History',
'History', 'Economics', 'Economics', 'Economics'],
'Score': [62, 47, 55, 74, 31, 77, 85, 63, 42, 62, 89, 85],
'score-ranked': [7.5, 10.0, 9.0, 5.0, 12.0, 4.0, 2.5, 6.0, 11.0, 7.5, 1.0, 2.5]
})
df.loc[len(df)] = ['Other', "", df[df['Score'] < 63]['Score'].sum(), ""]
df.drop(df[df['Score'] < 63].index, inplace=True)
print(df)
Output:
Name Subject Score score-ranked
3 Alisa Science 74 5.0
5 Cathrine Science 77 4.0
6 Alisa History 85 2.5
7 Bobby History 63 6.0
10 Bobby Economics 89 1.0
11 Cathrine Economics 85 2.5
12 Other 299