I am trying to combine all 3 pandas data frames together data, data2, data3 sort them in synchronous order in terms of date as well as removing all duplicate rows. No more than 1 date value must be the same however the date of '2021-10-21 00:03:00' is both present in data2 and data3 so there should only be a single row present in the output. What would I be able to add to the coed so that I achieve the Expected Output?
Code:
import pandas as pd
data = {'Unix Timesamp': [1444311600000, 1444311660000, 1444311720000],
'date': ['2015-10-08 13:40:00', '2015-10-08 13:41:00', '2015-10-08 13:42:00'],
'Symbol': ['BTCUSD', 'BTCUSD', 'BTCUSD'],
'Open': [10384.54, 10389.08,10387.15],
'High': [10389.08, 10389.08, 10388.36],
'Low': [10340.2, 10332.8, 10385]}
data2 = {'Unix Timesamp': [1634774460000, 1634774520000, 1634774580000],
'date': ['2021-10-21 00:01:00', '2021-10-21 00:02:00', '2021-10-21 00:03:00'],
'Symbol': ['BTCUSD', 'BTCUSD', 'BTCUSD'],
'High': [4939.97, 4961.75, 4964.33],
'Open': [4939.95, 4959.18,4964.33]}
data3 = {'Unix Timesamp': [1634774640000, 1634774640000],
'date': ['2021-10-21 00:03:00', '2021-10-21 00:04:00'],
'High': [4964.33, 4867.33],
'Symbol': ['BTCUSD', 'BTCUSD'],
'Open': [4964.33, 4800.2]}
dataset = pd.DataFrame.from_dict(data)
dataset2 = pd.DataFrame.from_dict(data2)
dataset3 = pd.DataFrame.from_dict(data3)
dataset.drop('Low',1).append([dataset2, dataset3], ignore_index=True).drop_duplicates()
Output:
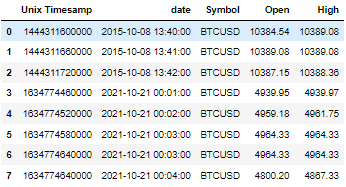
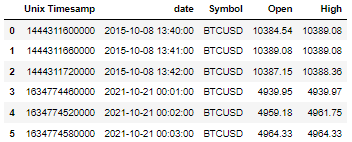
Expected Output (The 6th row in Output should not exist):
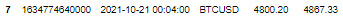
CodePudding user response:
The below code should satisfy your requirement. Make sure you include 'subset=['date']' within paranthesis of the .drop_duplicates() method. Example: .drop_duplicates(subset=['date'])
dataset.drop('Low',1).append([dataset2, dataset3],ignore_index=True).drop_duplicates(subset=['date'])
For more info refer https://pandas.pydata.org/docs/reference/api/pandas.DataFrame.drop_duplicates.html