I want to delete repeated values in the column called "employee" when the associated values in two columns called "ID" and " Year" are repeated. For example if this is the DataFrame:
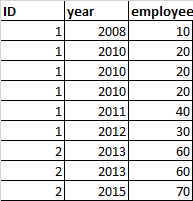
This is what i want to get:
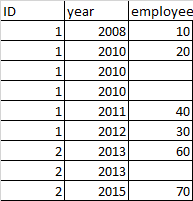
This is what I have done but it did not work:
df.loc[((df["ID"].duplicated()) & (df["year"].duplicated()) ), ["employee"]] = ''
I found the value of the "employee" was removed from some cells where it was not supposed to be removed.
CodePudding user response:
You can do
df.loc[df[['ID','year']].duplicated(),'employee'] = ''
CodePudding user response:
You can use np.where().
import numpy as np
df['employee'] = np.where(df[['ID','year']].duplicated(), '', df['employee'])