I'm beginner on scraping i'm trying to scrape data from this website (using beautifulSoup):
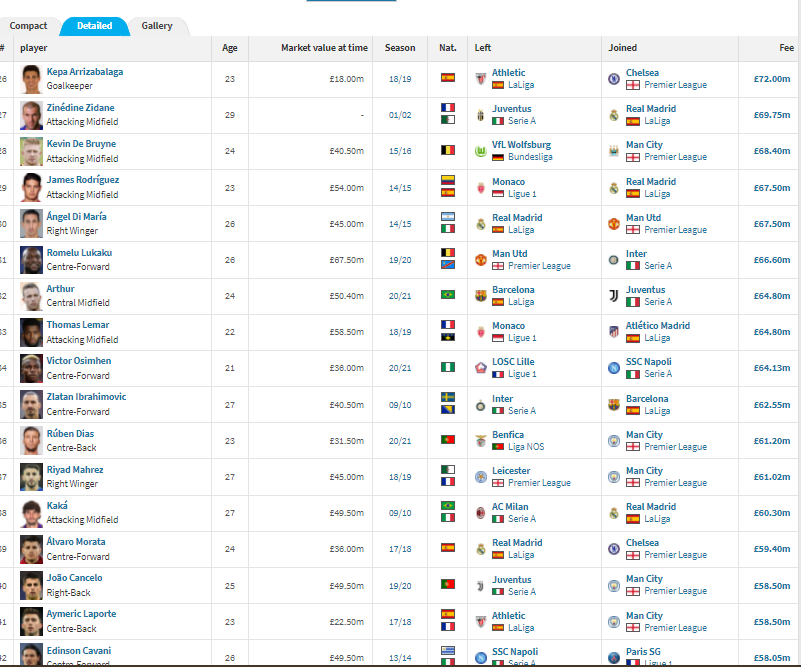
First i have recognised the elements i'm interested on like:
- playername
- Value
- age
- season
Second i created 1 object for each of them in order to put all these data into a pandas dataframe.
Here my code:
import requests
from bs4 import BeautifulSoup
import pandas as pd , numpy as np
headers = {'User-Agent':
'Mozilla/5.0 (X11; Linux x86_64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/47.0.2526.106 Safari/537.36'}
page = "https://www.transfermarkt.co.uk/transfers/transferrekorde/statistik?saison_id=alle&land_id=0&ausrichtung=&spielerposition_id=&altersklasse=&leihe=&w_s=&plus=1"
pageTree = requests.get(page, headers=headers)
pageSoup = BeautifulSoup(pageTree.content, 'html.parser')
Players = pageSoup.find_all("a", {"class": "spielprofil_tooltip"})
Values = pageSoup.find_all("td", {"class": "rechts hauptlink"})
Age = pageSoup.find_all("td", {"class": "zentriert"})
Finally while a for-loop i create a Pandas Dataframe with all the information i want:
PlayersList = []
ValuesList = []
value_pre = []
rank = []
age = []
season = []
team = []
missing = []
for i in range(0,25):
PlayersList.append(Players[i].text)
ValuesList.append(Values[i].text)
value_pre.append(Values_pre[2*i].text)
rank.append(Age[(5*i)].text)
age.append(Age[1 (5*i)].text)
season.append(Age[2 (5*i)].text)
missing.append(Age[3 (5*i)].text)
team.append(Age[4 (5*i)].text)
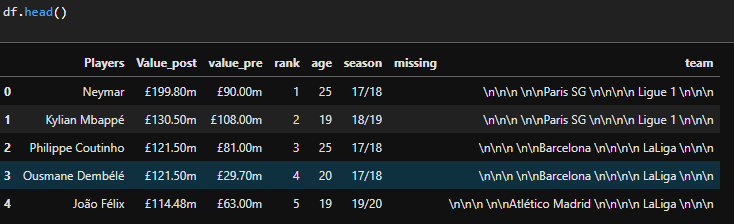
df = pd.DataFrame({"Players":PlayersList,"Value_post":ValuesList , "value_pre":value_pre , "rank": rank , "age":age , "season":season , "missing": missing , "team":team })
df.head()
The result i'm getting is a pandas Dataframe like this:
My problem:
if i put a number>25 on the range() within the for-loop i get this error:
---------------------------------------------------------------------------
IndexError Traceback (most recent call last)
<ipython-input-202-326415267fee> in <module>
9
10 for i in range(0,26):
---> 11 PlayersList.append(Players[i].text)
12 ValuesList.append(Values[i].text)
13 value_pre.append(Values_pre[2*i].text)
IndexError: list index out of range
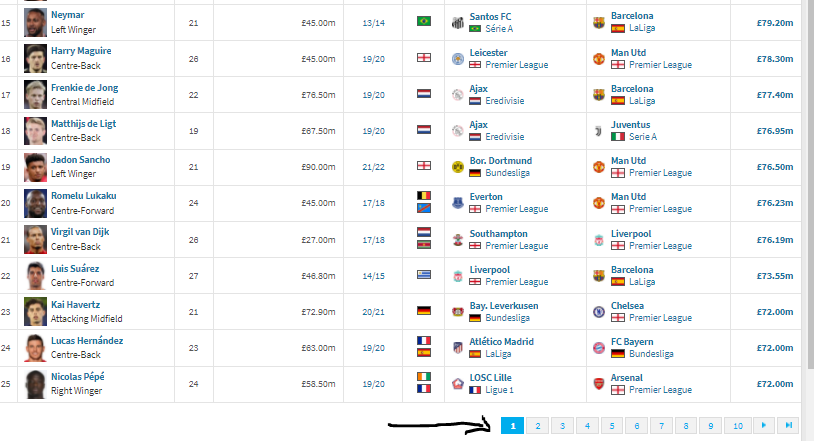
Since the table on the screen shows 25 player by each table page, i can just scrape the first 25 player informations.
If i go to the second page (see the screen) the url does not change, so how can i control this on python?
My goal is to extract all the players (and their informations) within the website.
CodePudding user response:
Just add for example &page=2 at the end of your url to query second page, so it becomes:
?saison_id=alle&land_id=0&ausrichtung=&spielerposition_id=&altersklasse=&leihe=&w_s=&plus=1&page=2
Note: I shortened url for readability.