I have a sample dataframe from my huge dataframe as shown given below.
import pandas as pd
import numpy as np
NaN = np.nan
data = {
'ID':['AAQRB','AAQRB','AAQRB',
'AHXSJ','AHXSJ','AHXSJ','GABOY','GABOY','GABOY','GHZGS','GHZGS','GHZGS'],
'Date':['10/18/2021 10:52:53 PM','10/18/2021 10:53:55 PM', '10/25/2021 5:55:43 PM',
'10/22/2021 10:37:06 PM','10/22/2021 10:38:22 PM','10/22/2021 10:39:56 PM',
'11/1/2021 1:27:15 AM','11/1/2021 1:28:45 AM','11/2/2021 8:53:39 PM',
'10/29/2021 11:13:57 PM', '10/29/2021 11:17:47 PM', '10/29/2021 11:19:15 PM'],
'Race_x':[NaN,NaN,NaN,NaN,NaN,1,NaN,NaN,1, NaN,NaN,1],
'Vaccine':['TRUE',NaN,NaN,'TRUE',NaN,NaN,'TRUE',NaN,NaN,'FALSE',NaN,NaN],
'Study_activity':
[NaN,'continue',NaN,NaN,'continue',NaN,NaN,'continue',NaN,NaN,'continue',NaN],
'Who_Contacted':
[NaN,NaN,'WeContacted',NaN,NaN,'WeContacted',NaN,NaN,NaN,NaN,NaN,'WeContacted']}
test_df = pd.DataFrame(data)
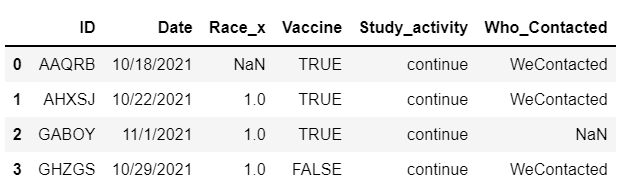
Goal is to get all the first values for each ID and filter the several rows of participant to a single row with all information. The final dataframe should look like the image given below.
CODE TRIED
I tried using the Grouper() function, and the code is given below.
test_df['Date'] = pd.to_datetime(test_df['Date'])
test_df1 = (test_df.groupby(['ID', pd.Grouper(key='Date', freq='D')])
.agg("first")
.reset_index())
baseline_df = test_df1[~test_df1.duplicated(subset = ['ID'], keep='first')]
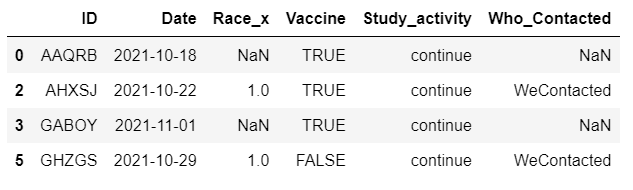
But the problem with this is, if I use freq='D', then the Race_x values are missed which are entered the next day. the output looks like the image shown below.
If I use freq='M' or freq='Y', the other values are captured, however the Dates column values are changed, and we get the date of end of month for each ID as shown below.
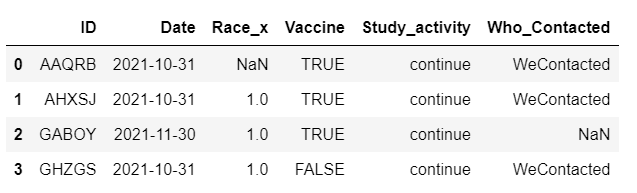
The final 'Date' column should be the first entry of the 'date' for each ID and it should not change.
Any help is greatly appreciated. Thank you!
CodePudding user response:
Looks like you want to groupby ID only and aggregate Date as first, everything else as whenever you have a valid value.
Assuming all of Race_x, Vaccine, Study_activity, Who_Contacted is always a single non-NaN value for an ID. You can bfill first before aggregation.
This will collect the non-NaN value to the first entry for a participant.
test_df['Date'] = pd.to_datetime('Date').dt.date
test_df.update(test_df.groupby('ID').bfill())
Then, try aggregation.
test_df.groupby('ID').first().reset_index()
>>> ID Date Race_x Vaccine Study_activity Who_Contacted
0 AAQRB 2021-10-18 NaN TRUE continue WeContacted
1 AHXSJ 2021-10-22 1.0 TRUE continue WeContacted
2 GABOY 2021-11-01 1.0 TRUE continue NaN
3 GHZGS 2021-10-29 1.0 FALSE continue WeContacted
CodePudding user response:
Create a virtual column to group by month:
>>> test_df.assign(month=test_df['Date'].dt.strftime('%Y-%m')) \
.groupby(['ID', 'month']).agg('first') \
.droplevel(1).reset_index() \
.assign(Date=lambda x: x['Date'].dt.date)
ID Date Race_x Vaccine Study_activity Who_Contacted
0 AAQRB 2021-10-18 NaN TRUE continue WeContacted
1 AHXSJ 2021-10-22 1.0 TRUE continue WeContacted
2 GABOY 2021-11-01 1.0 TRUE continue None
3 GHZGS 2021-10-29 1.0 FALSE continue WeContacted