I have a dataframe with some recurring values in one column. I want to group by that column and sum the other columns. The dataframe looks like this:
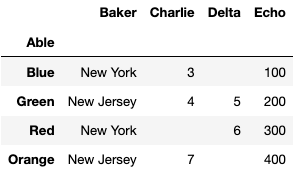
The result should group on 'Baker' and sum the other three columns. I've tried various flavors of groupby and pivot_table. They return the correct two rows (New York and New Jersey) but they only return 'Baker' and the sum for the rightmost column, 'Echo.' Like this:

How do I return all the columns, ideally without listing them individually in the code?
CodePudding user response:
Use pivot_table:
>>> df.pivot_table(index='Baker', values=['Charlie', 'Delta', 'Echo'],
aggfunc='sum').reset_index()
Baker Charlie Delta Echo
0 New Jersey 11.0 5.0 600
1 New York 3.0 6.0 400
Ensure your columns C, D, E are numeric, try df.replace('', 0) or df.fillna(0) to fill your blank cells.
CodePudding user response:
Replace the space with 0 and agg sum. This will depend on what dype, the last three columns are. I repoduced df for you, feel free to edit if I got the dtypes wrong and edit the question. The forum will guide you.
Dataframe
df=pd.DataFrame({'Baker':[ 'New York', 'New Jersey', 'New York', 'New Jersey'], 'Charlie':[3,4,'',7], 'Delta':['',5,6,''],'Echo':[100,200,300,400]})
Code
df.replace('',0).groupby('Baker').agg('sum')
Output
Charlie Delta Echo
Baker
New Jersey 11 5 600
New York 3 6 400