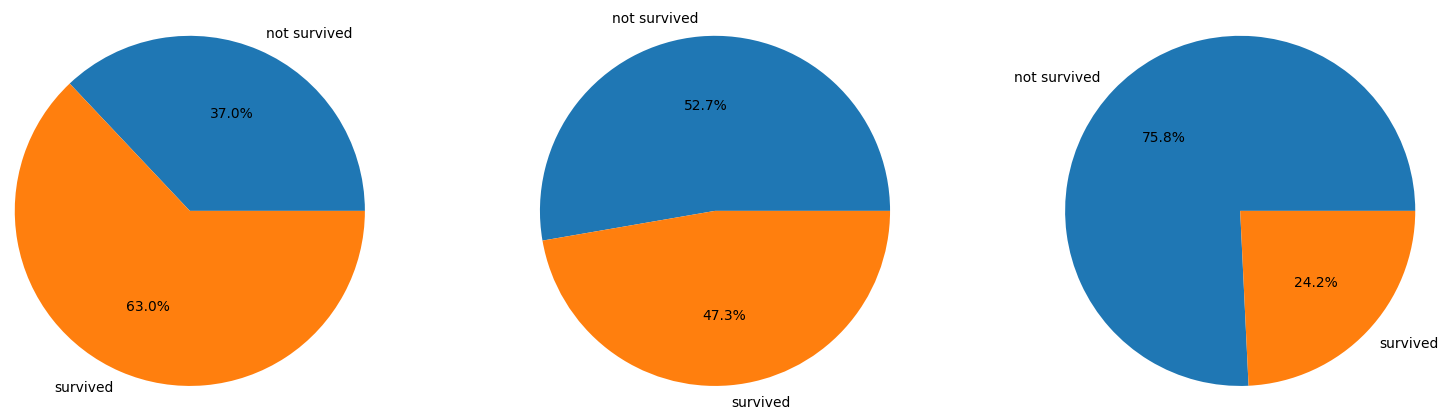
In titanic dataset, I need to create a chart that shows the percentage of passengers for all class who survived. Also it should have three pie charts. class 1 survived and not-survived, class 2 survived and not-survived, class 3.
How can make this happen? I already tried this type of code but it produces wrong values.
import pandas as pd
import seaborn as sns # for dataset
df_titanic = sns.load_dataset('titanic')
survived pclass sex age sibsp parch fare embarked class who adult_male deck embark_town alive alone
0 0 3 male 22.0 1 0 7.2500 S Third man True NaN Southampton no False
1 1 1 female 38.0 1 0 71.2833 C First woman False C Cherbourg yes False
2 1 3 female 26.0 0 0 7.9250 S Third woman False NaN Southampton yes True
c1s = len(df_titanic[(df_titanic.pclass==1) & (df_titanic.survived==1)].value_counts())
c2ns = len(df_titanic[(df_titanic.pclass==1) & (df_titanic.survived==0)].value_counts())
this code produce true values but I need that in 3 pie chart
df_titanic.groupby(['pclass' ,'survived']).size().plot(kind='pie', autopct='%.2f')
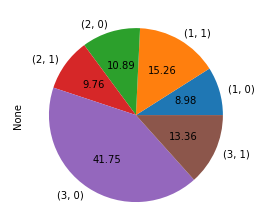
class: 1,2,3 survived: 0,1
CodePudding user response:
- The correct way to get subplots using pandas, is to reshape the dataframe.
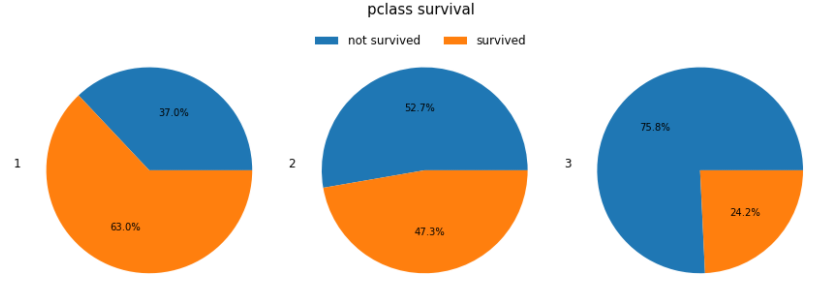
Unformatted Figure
axes = ct.plot(kind='pie', autopct='%.1f%%', subplots=True, figsize=(12, 5), labels=["not survived", "survived"])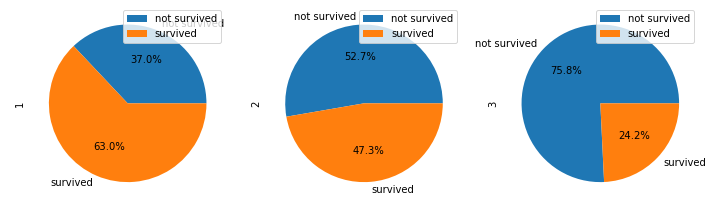
CodePudding user response:
Code:
labels = ["not survived", "survived"] fig, axs = plt.subplots(1,3) axs[0].pie(df_titanic[df_titanic["Pclass"] == 1].groupby(["Survived"]).size(), labels=labels, autopct='%1.1f%%') axs[1].pie(df_titanic[df_titanic["Pclass"] == 2].groupby(["Survived"]).size(), labels=labels, autopct='%1.1f%%') axs[2].pie(df_titanic[df_titanic["Pclass"] == 3].groupby(["Survived"]).size(), labels=labels, autopct='%1.1f%%') plt.show()Results: