I am attempting to scrape a webpage using the following code, however, I am getting an error due to 'mis-matched' rows. What I am trying to achieve is a pandas dataframe which contains the name of a course and then the full-time code, full-time URL, part-time code, part-time URL. The problem is that not all of the courses have both full and part-time courses so when I have tried to replace the blanks with "NA" to get the same number of rows, it produces the error.
The following code provides the output for all of the courses with both full time and part time course, and this code does not produce an error as it only allows courses with all 5 elements present:
#Import modules
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
import seaborn as sns
%matplotlib inline
from urllib.request import urlopen
from bs4 import BeautifulSoup
from urllib.request import urlopen
from bs4 import BeautifulSoup
#Specify URL
url = "http://eecs.qmul.ac.uk/postgraduate/programmes"
html = urlopen(url)
# Print the first 10 table rows
rows = soup.find_all('tr')
print(rows[:10])
#Create data frame
df = pd.DataFrame(columns = ['Course Name', 'Part Time Code', 'Part Time URL', 'Full Time Code', 'Full Time URL'])
#Create loop to go through all rows
for row in rows:
courses = row.find_all("td")
# The fragments list will store things to be included in the final string, such as the course title and its URLs
fragments = []
for course in courses:
if course.text.isspace():
continue
# Add the <td>'s text to fragments
fragments.append(course.text)
# Try and find an <a> tag
a_tag = course.find("a")
if a_tag:
# If one was found, add the URL to fragments
fragments.append(a_tag["href"])
# Make a string containing every fragment with ", " spacing them apart.
cleantext = ", ".join(fragments)
#Add rows to the dataframe if the information exists
if len(fragments) == 5:
df.loc[len(df.index)] = fragments
df.head(30)
This is the output:
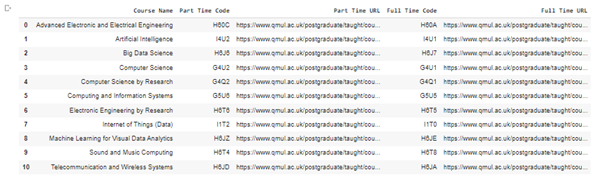
And this is the method I have used to try to replace the blanks with NA to ensure there are 5 elements in each line:
#Import modules
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
import seaborn as sns
%matplotlib inline
from urllib.request import urlopen
from bs4 import BeautifulSoup
from urllib.request import urlopen
from bs4 import BeautifulSoup
#Specify URL
url = "http://eecs.qmul.ac.uk/postgraduate/programmes"
html = urlopen(url)
# Print the first 10 table rows
rows = soup.find_all('tr')
#Create data frame
df = pd.DataFrame(columns = ['Course Name', 'Part Time Code', 'Part Time URL', 'Full Time Code', 'Full Time URL'])
#Create loop to go through all rows
for row in rows:
courses = row.find_all("td")
# The fragments list will store things to be included in the final string, such as the course title and its URLs
fragments = []
for course in courses:
if course.text.isspace():
fragments.append("NA")
else:
# Add the <td>'s text to fragments
fragments.append(course.text)
# Try and find an <a> tag
a_tag = course.find("a")
if a_tag:
# If one was found, add the URL to fragments
fragments.append(a_tag["href"])
else:
fragments.append("NA")
# Make a string containing every fragment with ", " spacing them apart.
cleantext = ", ".join(fragments)
#Add rows to the dataframe if the information exists
if len(fragments) > 0:
df.loc[len(df.index)] = fragments
df.head(30)
And this is the error that it is returned:
ValueError Traceback (most recent call last)
<ipython-input-28-94bb08463416> in <module>()
38 #Add rows to the dataframe if the information exists
39 if len(fragments) > 0:
---> 40 df.loc[len(df.index)] = fragments
41 df.head(30)
2 frames
/usr/local/lib/python3.7/dist-packages/pandas/core/indexing.py in _setitem_with_indexer_missing(self, indexer, value)
1854 # must have conforming columns
1855 if len(value) != len(self.obj.columns):
-> 1856 raise ValueError("cannot set a row with mismatched columns")
1857
1858 value = Series(value, index=self.obj.columns, name=indexer)
ValueError: cannot set a row with mismatched columns
Would you be able to identify how I can resolve this issue so that courses without a parttime code or URL are still included in the dataframe please?
CodePudding user response:
It's much, much simpler than that. Find the table by id, then feed the prettify-ed version straight into Pandas IO. Pandas handles NaNs out of the box.
soup = BeautifulSoup(urlopen('http://eecs.qmul.ac.uk/postgraduate/programmes'))
table = soup.find("table", {"id":"PGCourse"})
df = pd.read_html(table.prettify())[0]
# rename columns
df.columns = ['Course Name', 'Part Time Code', 'Full Time Code']
Edit: OK, then to get the links you do need to iterate:
pt_links, ft_links = [], []
for row in table.find_all("tr")[1:]:
row_data = row.find_all("td")
pt, ft = row_data[1], row_data[2]
pt_link = pt.find_all('a')
pt_links.append('' if len(pt_link) == 0 else pt_link[0]['href'])
ft_link = ft.find_all('a')
ft_links.append('' if len(ft_link) == 0 else ft_link[0]['href'])
df['Part Time URL'] = pt_links
df['Full Time URL'] = ft_links
# rearrange the columns (optional)
df = df[['Course Name', 'Part Time Code', 'Part Time URL', 'Full Time Code', 'Full Time URL']]