I need to remove columns from a pandas data frame with headers containing a specific string pattern (.1). The code I have so far does this but also removes columns with headers containing the pattern 11, which I want to keep:
DX_totals = DX_totals[DX_totals.columns.drop(list(DX_totals.filter(regex='[.|1]{2}')))]
How do I adjust the code to drop only columns with headers containing the pattern .1?
The data are in the format:
Well ID PlantFlow PlantChrome DXRunTime ME01 ME02 ME03 ME04 ME05 ME06 ... MJ22.1 MJ23.1 MJ24.1 MJ25.1 MJ26.1 MJ27.1 MJ28.1 MJ29.1 MJ30.1 DX
0 2021-01-01 00:01:00 91668344 5426653 22092 980729 1117150 103164 287075 2747259 1885657 ... -44.115395 -40.537468 0 -31.149002 -61.727837 0 0 -68.037201 -63.994675 22092
1 2021-01-02 00:00:00 92506192 5471052 22332 993835 1131376 0 0 2777229 0 ... -44.074005 -40.616493 0 -32.239822 -61.803848 0 0 -68.023262 -63.993423 22332
2 2021-01-03 00:00:00 93343920 5515476 22572 1006940 1145596 0 0 2807222 0 ... -43.943542 -40.857651 0 -31.181437 -61.927658 0 0 -68.01889 -63.997154 22572
The desired outcome would look like:
Well ID PlantFlow PlantChrome DXRunTime ME01 ME02 ME03 ME04 ME05 ME06 ME11 ...
0 2021-01-01 00:01:00 91668344 5426653 22092 980729 1117150 103164 287075 2747259 2748354 ...
1 2021-01-02 00:00:00 92506192 5471052 22332 993835 1131376 0 0 2777229 0 2777350 ...
Thank you!
CodePudding user response:
I created a dummy df with some of your headers:
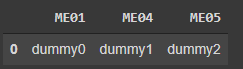
df = pd.DataFrame({'ME01': ['dummy0'], 'ME04': ['dummy1'], 'ME05': ['dummy2'], 'MJ22.1': ['dummy3'], 'MJ24.1': ['dummy4']})
Then changed the regex:
df[df.columns.drop(list(df.filter(regex=r'\.1')))]
output: