I'm trying to extract information from a table with selenium.
I got the rows:
rows = driver.find_elements_by_xpath('//tbody/tr')
And I'm trying to get two specific cells within the row:
for r in rows:
diccionario["property1"] = driver.find_element_by_xpath(xpath).text
diccionario["property2"] = driver.find_element_by_xpath(xpath).text
with open("bbdd.json", "a", encoding="utf-8") as bd:
json.dump(diccionario, bd, ensure_ascii=False, indent=4)
However, it will only return the information from the first row (repeated as many times as the number of rows)
Is there a way to "force" the code to find the elements within the row we're currently iterating in the for loop?
Code
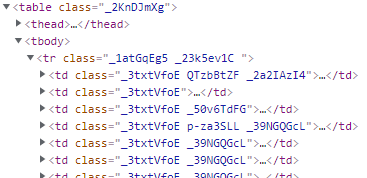
All the trs (rows) code look the same.
The tds/cells that I need are the first two (the classes look the same for every td in the different rows as well).
CodePudding user response:
I was focused on trying to access the cell itself. However, I changed my mind and tried to reach the content from the "webelement parent" (the row itself).
The row's text property had the information that I needed.
The only problem was that I had to parse some text (not that hard to do). So in the end I didn't need to access the different tds.