I have about 20million rows text data and want to label it based on several keywords (about 100k keywords). My text data was look like this
| text |
|---|
| my car was broken |
| nobody knows |
| the fish is so beautiful |
While the keywords is look like this
| keywords |
|---|
| car |
| beautiful |
| know |
| journey |
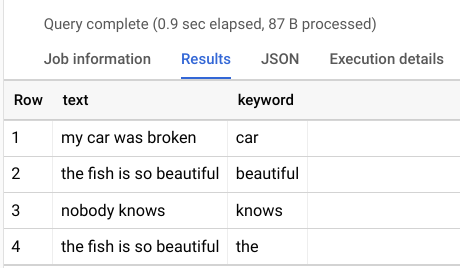
My expected output is look like this, where I will regex the text column using keywords data.
| text | keywords |
|---|---|
| my car was broken | car |
| nobody knows | know |
| the fish is so beautiful | beautiful |
I use regex like in 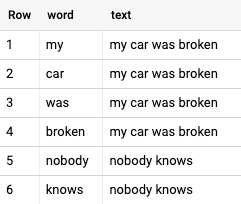
Cross the data:
SELECT word_text.text, raw_keywords.keyword
FROM word_text, raw_keywords
WHERE word_text.word = raw_keywords.keyword
CodePudding user response:
The following query returns what you want spliting the text into words and doing a INNER JOIN on the keywords table, without having to create a new table.
WITH splited AS (
SELECT SPLIT(text, ' ') AS text_split, text FROM project.dataset.text_tab
)
SELECT text, keyword
FROM (
SELECT text, word_inside FROM splited, UNNEST(text_split) AS word_inside
)
INNER JOIN
`project.dataset.keywords`
ON
keyword = word_inside;
- Tables:

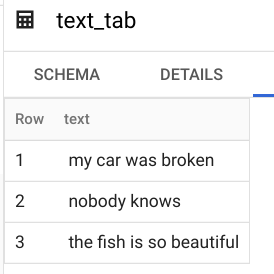
- Result: