I have a dataframe with multiple attributes, some are repeating. I want to select the rows based on the max value in one column - but return the row having that value (not the max of every column). How??
Here's a sample:
df = pd.DataFrame({'Owner': ['Bob', 'Jane', 'Amy',
'Steve','Kelly'],
'Make': ['Ford', 'Ford', 'Jeep',
'Ford','Jeep'],
'Model': ['Bronco', 'Bronco', 'Wrangler',
'Model T','Wrangler'],
'Max Speed': [80, 150, 69, 45, 72],
'Customer Rating': [90, 50, 91, 75, 99]})
this gives us:
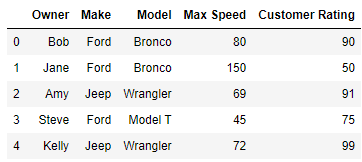
I want the row having the max(customer rating) for each Make/Model.
Like this:
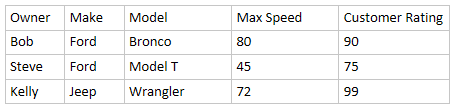
Note this is NOT the same as df.groupby(['Make','Model']).max()
--> How do I do this?
CodePudding user response:
A variation of your answer using idxmax:
>>> df.loc[df.groupby(['Make', 'Model'])['Customer Rating'].idxmax()]
Owner Make Model Max Speed Customer Rating
0 Bob Ford Bronco 80 90
3 Steve Ford Model T 45 75
4 Kelly Jeep Wrangler 72 99
Another solution without groupby:
>>> df.sort_values('Customer Rating') \
.drop_duplicates(['Make', 'Model'], keep='last') \
.sort_index()
Owner Make Model Max Speed Customer Rating
0 Bob Ford Bronco 80 90
3 Steve Ford Model T 45 75
4 Kelly Jeep Wrangler 72 99
CodePudding user response:
I found an answer! I'm leaving the question up in case anyone else didn't recognize it as well.
Check out this post:
this also worked fine:
def using_sort(df):
df = df.sort_values(by=['Customer Rating'], ascending=False, kind='mergesort')
return df.groupby(['Make', 'Model'], as_index=False).first()
CodePudding user response:
Propagate maximum in each desired group and filter out those equal to Customer Rating
df[df['Customer Rating']==df.groupby(['Make','Model'])['Customer Rating'].transform('max')]
Owner Make Model Max Speed Customer Rating
0 Bob Ford Bronco 80 90
3 Steve Ford Model T 45 75
4 Kelly Jeep Wrangler 72 99