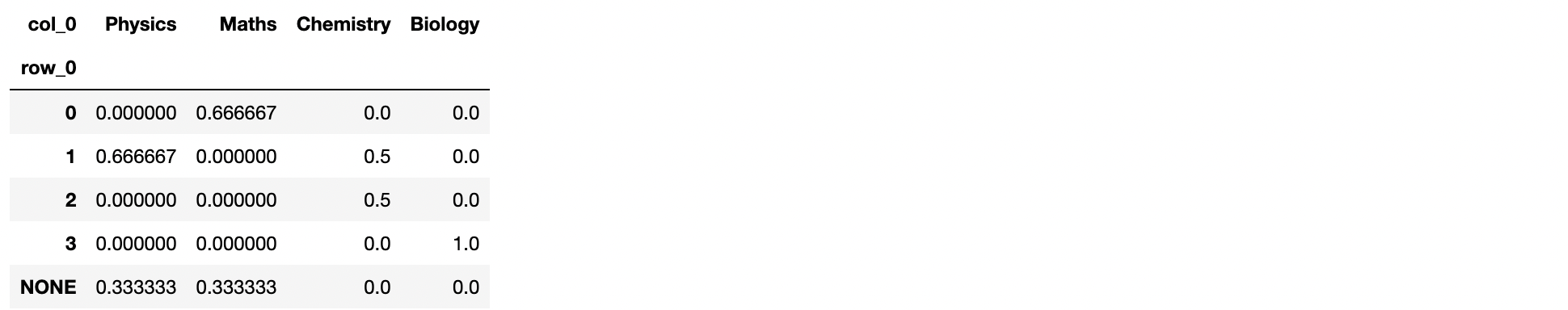I have a DataFrame which looks like this:
df = Pd.DataFrame({'Correct Prediction (Insert None if none of the predictions are correct)':[1,0,1,4,'NONE',1,0,3,2,'NONE'],
'Subject':['Physics','Maths','Chemistry','Biology','Physics','Physics','Maths','Biology','Chemistry','Maths']})
So I want to get all the entries to see How much % of each Subject is in 0,1,2,3,4 and NONE. Let us suppose that how much of the Physics are in NONE so I can get the Total Questions which are in NONE AND belong to Physics and then divide by the Total Number of Physics Questions. I can get this the hard way using the code below:
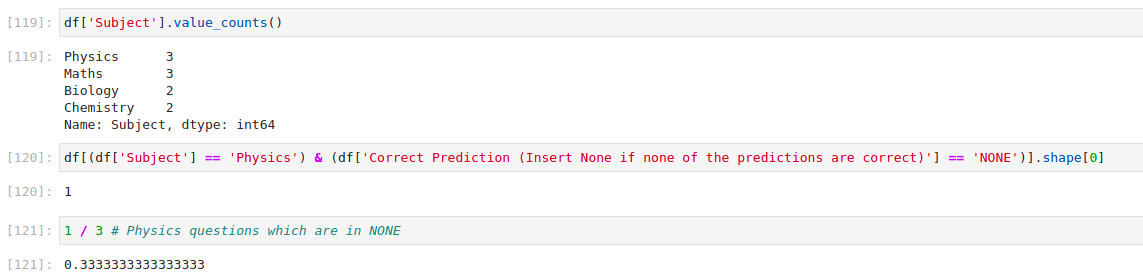
df['Subject'].value_counts()
df[(df['Subject'] == 'Physics') & (df['Correct Prediction (Insert None if none of the predictions are correct)'] == position)].shape[0]
But what is the easy and better way to do this?
I tried
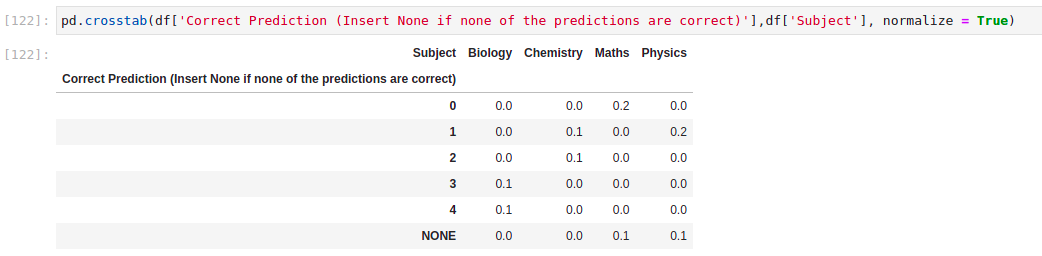
pd.crosstab(df['Correct Prediction (Insert None if none of the predictions are correct)'],df['Subject'], normalize = True)
But it gives me weird values such as 0.1 instead of 0.333
I can do this in loop as:
counts = df['Subject'].value_counts()
for index in counts.index:
print(f"Results for: {index}\n")
total_count = counts[index]
for position in [0,1,2,3,4,'NONE']:
i = df[(df['Subject'] == index) & (df['Correct Prediction (Insert None if none of the predictions are correct)'] == position)].shape[0]
print(f"Position {position} : {round((i / total_count)*100, 2)}%")
print("-"*50,'\n')
CodePudding user response:
Try the following:
correct_prediction = pd.Categorical([df['Correct Prediction (Insert None if none of the predictions are correct)'].tolist(), categories=[0,1,2, 3, 'NONE'])
subject = pd.Categorical(df['Subject'].tolist(), categories=['Physics', 'Maths', 'Chemistry', 'Biology'])
pd.crosstab(correct_prediction, subject, normalize='columns')