I have two dataframe df1 and subdf.
df1 looks something like this:
from pandas import Timestamp, Timedelta
df = pd.DataFrame({'station_key': {1300234: 'CV000011', 1300235: 'CV000011'},'charger_key': {1300234: 'CV00001101', 1300235: 'CV00001101'},'cid': {1300234: '01', 1300235: '01'},'x': {1300234: '33.489125', 1300235: '33.489125'},'y': {1300234: '126.487631', 1300235: '126.487631'},'snm': {1300234: '에코티엘(제주)', 1300235: '에코티엘(제주)'},'addr': {1300234: '제주특별자치도 제주시 연동 251-69외 ',1300235: '제주특별자치도 제주시 연동 251-69외 '},'addr_jibun': {1300234: '-', 1300235: '-'},'started_at': {1300234: Timestamp('2020-11-03 20:56:31'),1300235: Timestamp('2020-11-03 23:10:12')},'ended_at': {1300234: Timestamp('2020-11-03 23:10:12'),1300235: Timestamp('2020-11-03 23:40:12')},'status': {1300234: '2', 1300235: '1'},'day': {1300234: 'Tuesday', 1300235: 'Tuesday'},'time_usage': {1300234: Timedelta('0 days 02:13:41'),1300235: Timedelta('0 days 00:30:00')},'start': {1300234: Timestamp('2020-11-03 00:00:00'),1300235: Timestamp('2020-11-03 00:00:00')},'end': {1300234: Timestamp('2020-11-03 00:00:00'),1300235: Timestamp('2020-11-03 00:00:00')},'start_hour': {1300234: 20, 1300235: 23},'end_hour': {1300234: 23, 1300235: 23},'start_minute': {1300234: 56, 1300235: 10},'end_minute': {1300234: 10, 1300235: 40}})
And the subdf looks something like this:
subdf = pd.DataFrame({'start': {1300234: Timestamp('2020-11-03 00:00:00'),4849001: Timestamp('2020-11-03 00:00:00')},'station_key': {1300234: 'CV000011', 4849001: 'CV000271'},'charger_key': {1300234: 'CV00001101', 4849001: 'CV00027101'},'cid': {1300234: '01', 4849001: '01'},'x': {1300234: '33.489125', 4849001: '33.452903'},'y': {1300234: '126.487631', 4849001: '126.572552'},'snm': {1300234: '에코티엘(제주)', 4849001: '제주첨단과학단지(엘리트빌딩)'},'0_occupation': {1300234: 0, 4849001: 0},'1_occupation': {1300234: 0, 4849001: 0},'2_occupation': {1300234: 0, 4849001: 0},'3_occupation': {1300234: 0, 4849001: 0},'4_occupation': {1300234: 0, 4849001: 0},'5_occupation': {1300234: 0, 4849001: 0},'6_occupation': {1300234: 0, 4849001: 0},'7_occupation': {1300234: 0, 4849001: 0},'8_occupation': {1300234: 0, 4849001: 0},'9_occupation': {1300234: 0, 4849001: 0},'10_occupation': {1300234: 0, 4849001: 0},'11_occupation': {1300234: 0, 4849001: 0},'12_occupation': {1300234: 0, 4849001: 0},'13_occupation': {1300234: 0, 4849001: 0},'14_occupation': {1300234: 0, 4849001: 0},'15_occupation': {1300234: 0, 4849001: 0},'16_occupation': {1300234: 0, 4849001: 0},'17_occupation': {1300234: 0, 4849001: 0},'18_occupation': {1300234: 0, 4849001: 0},'19_occupation': {1300234: 0, 4849001: 0},'20_occupation': {1300234: 0, 4849001: 0},'21_occupation': {1300234: 0, 4849001: 0},'22_occupation': {1300234: 0, 4849001: 0},'23_occupation': {1300234: 0, 4849001: 0}})
The _occupation columns represent the hour so there are 24 columns like that ranging from 0_occupation to 23_occupation
The function that I am trying to apply to df1 is as follows:
def time_add(x):
s_date = x['start']
e_date = x['end']
s_hour = x['start_hour']
e_hour = x['end_hour']
s_min = x['start_minute']
e_min = x['end_minute']
if(s_date == e_date):
first_range = list(range(s_hour 1, e_hour))
subdf.loc[(subdf["charger_key"] == x['charger_key']) & (subdf["start"] == s_date), str(s_hour) "_occupation"] =((60 - s_min)/60)*100
for i in first_range:
subdf.loc[(subdf["charger_key"] == x['charger_key']) & (subdf["start"] == s_date), str(i) "_occupation"] = 1
subdf.loc[(subdf["charger_key"] == x['charger_key']) & (subdf["start"] == s_date), str(e_hour) "_occupation"] =(e_min/60)*100
else:
first_range = list(range(s_hour 1, 24))
subdf.loc[(subdf["charger_key"] == x['charger_key']) & (subdf["start"] == s_date), str(s_hour) "_occupation"] =((60 - s_min)/60)*100
for i in first_range:
subdf.loc[(subdf["charger_key"] == x['charger_key']) & (subdf["start"] == s_date), str(i) "_occupation"] = 1
second_range = list(range(0, e_hour))
for i in second_range:
subdf.loc[(subdf["charger_key"] == x['charger_key']) & (subdf["start"] == s_date 1), str(i) "_occupation"] = 1
subdf.loc[(subdf["charger_key"] == x['charger_key']) & (subdf["start"] == s_date 1), str(e_hour) "_occupation"] =(e_min/60)*100
However when I try to apply this by doing time_add(df1) an error is raised:
The truth value of a Series is ambiguous. Use a.empty, a.bool(), a.item(), a.any() or a.all().
I looked this up and this error seems to occur when using and and or instead of & and | but this isn't the case in my function.
The full traceback of the error is as follows
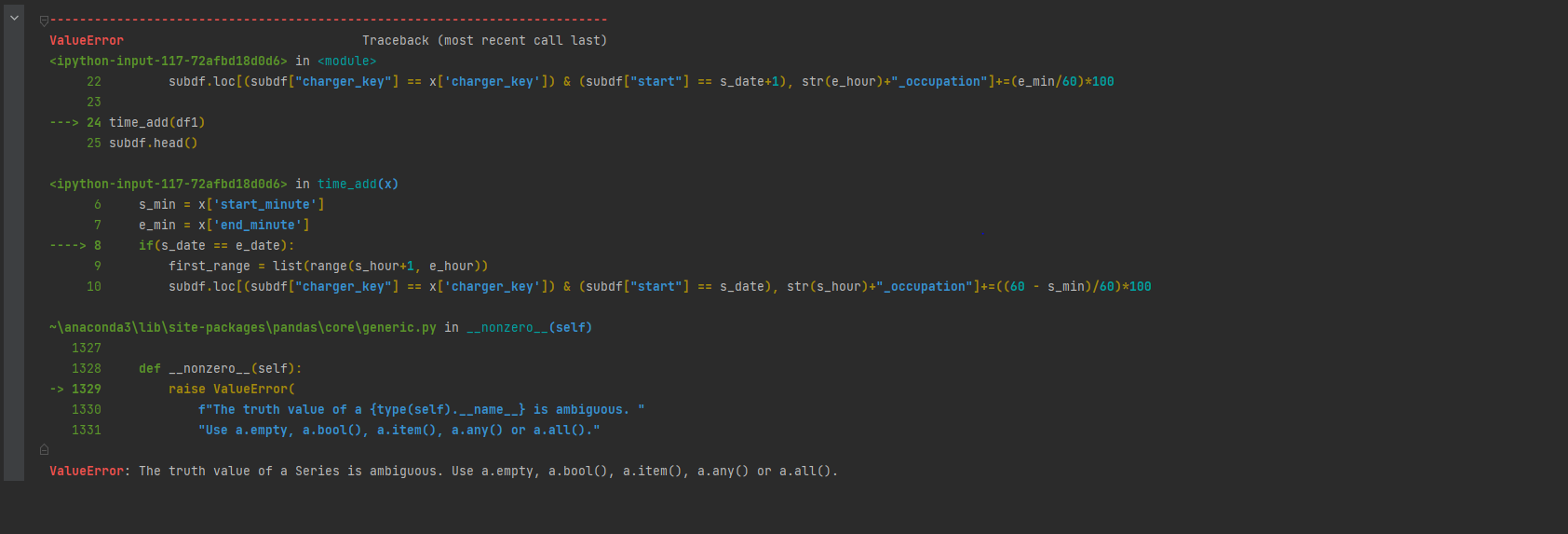
Thank you in advance!!
CodePudding user response:
In this line:
if(s_date == e_date):
The s_date and e_date variables are not single values, but entire columns from your Pandas data frame. What does it mean when you are comparing them? Do you want to check if all values in one column are equal to the other? Or do you want to check if at least one value is equal to the corresponding one? Or do you want to do different things to the rows depending on whether the corresponding values in those two columns are equal?
if (s_date == e_date).all():
# True if ALL values are equal.
Or,
if (s_date == e_date).any():
# True if AT LEAST ONE value is equal.
CodePudding user response:
As Dietrich pointed out, s_date and e_date, and all the other variables declared at the top of your function, are Series's. They're whole columns from your dataframe. But I suspect that's not what you what. You're trying to run time_add for each row. But you're not doing that, because you're calling time_add(df1). There it will be executed on the whole dataframe, and indexing it will return a whole column.
Change
time_add(df1)
to
df = df1.apply(time_add, axis=1)