I'm new to the library and am trying to figure out how to add columns to a pivot table with the mean and standard deviation of the row data for the last three months of transaction data.
Here's the code that sets up the pivot table:
previousThreeMonths = [prev_month_for_analysis, prev_month2_for_analysis, prev_month3_for_analysis]
dfPreviousThreeMonths = df[df['Month'].isin(previousThreeMonths)]
ptHistoricalConsumption = dfPreviousThreeMonths.pivot_table(dfPreviousThreeMonths,
index=['Customer Part #'],
columns=['Month'],
aggfunc={'Qty Shp':np.sum}
)
ptHistoricalConsumption['Mean'] = ptHistoricalConsumption.mean(numeric_only=True, axis=1)
ptHistoricalConsumption['Std Dev'] = ptHistoricalConsumption.std(numeric_only=True, axis=1)
ptHistoricalConsumption
The resulting pivot table looks like this:
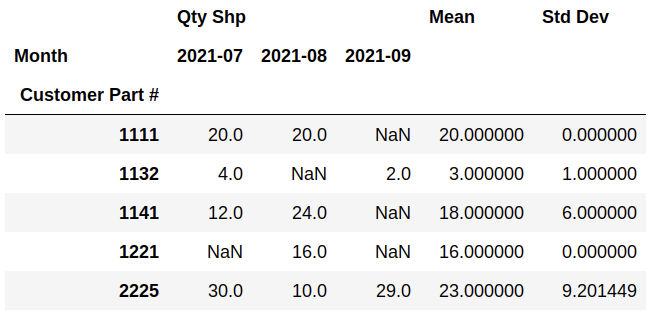
The problem is that the standard deviation column is including the Mean in its calculations, whereas I just want it to use the raw data for the previous three months. For example, the Std Dev of part number 2225 should be 11.269, not 9.2.
I'm sure there's a better way to do this and I'm just missing something.
CodePudding user response:
One way would be to remove the Mean column temporarily before call .std():
ptHistoricalConsumption['Std Dev'] = ptHistoricalConsumption.drop('Mean', axis=1).std(numeric_only=True, axis=1)
That wouldn't remove it from the permanently, it would just remove it from the copy fed to .std().