I have two dataframes containing Groundtruth and Predicted labels. Let's pretend I have 6 class labels. Let's say these dataframes look like this:
Groundtruth :
|0|0|0|0|1|1|1|2|2|3|3|3|4|4|4|5|5|5|5|5|5|5|
Predicted :
|0|0|0|1|1|1|1|1|2|3|3|4|4|4|5|5|5|5|5|5|5|5|
If the temporal interval between the frame from which the action begins and the frame where the classifier finally make decision is h, and the whole length of an action is H, then the latency of this action is defined as h/H.
Here's a figure that explains latency :
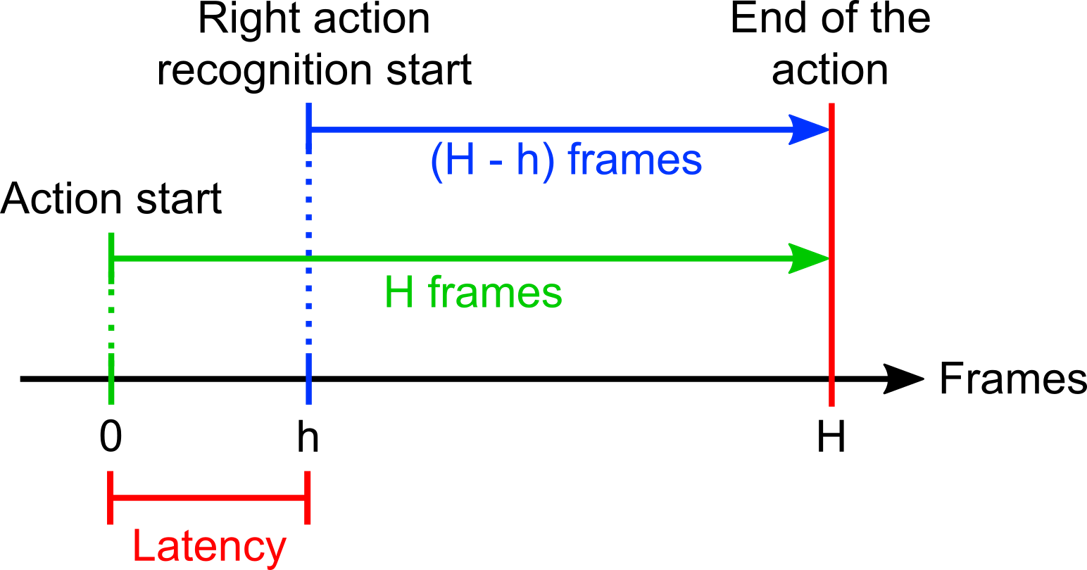
I want to compute average latency of classes based on these two dataframes.
Here's what I have tried so far :
groundtruth = pd.read_csv('groundtruth .csv', sep=",", header=None).transpose()
prediction = pd.read_csv('prediction .csv', sep=",", header=None).transpose()
average_latency=0
current_latency=0
changes_groundtruth = {}
changes_prediction = {}
for col in groundtruth.columns:
changes_groundtruth[col] = [0] [idx for idx, (i, j) in enumerate(zip(groundtruth[col], groundtruth[col][1:]), 1) if i != j]
for col in prediction.columns:
changes_prediction[col] = [0] [idx for idx, (i, j) in enumerate(zip(prediction[col], prediction[col][1:]), 1) if i != j]
for i in range(len(changes_groundtruth[0])):
for j in range(len(changes_prediction[0])):
if (changes_groundtruth[0][i] == changes_prediction[0][j]):
if (groundtruth[0].loc[i] == prediction[0].loc[j]):
current_latency = (changes_prediction[0][j] - changes_groundtruth[0][i])
elif (changes_groundtruth[0][i] < changes_prediction[0][j]):
if (groundtruth[0].loc[i] == prediction[0].loc[j]):
current_latency = (changes_prediction[0][j] - changes_groundtruth[0][i])
I don't know if this correct or not. How can I compute latency the the best/correct way ?
CodePudding user response:
IIUC, and assuming gt and pred the Series of data:
gt = groundtruth[0]
pred = prediction[0]
You can use groupby on the Series themselves and idxmin to get the index of the first element and size the H, the rest is simple arthmetics:
g = gt.groupby(gt)
(pred.groupby(pred).idxmin()-g.idxmin())/g.size()
output:
0 0.000000
1 -0.333333
2 0.500000
3 0.000000
4 -0.333333
5 -0.142857